AMD to Build Next-Gen I/O Dies on Samsung 4nm, Not TSMC N4P
Back in January, we covered a report about AMD designing its next-generation "Zen 6" CCDs on a 3 nm-class node by TSMC, and developing a new line of server and client I/O dies (cIOD and sIOD). The I/O die is a crucial piece of silicon that contains all the uncore components of the processor, including the memory controllers, the PCIe root complex, and Infinity Fabric interconnects to the CCDs and multi-socket connections. Back then it was reported that these new-generation I/O dies were being designed on the 4 nm silicon fabrication process, which was interpreted as being AMD's favorite 4 nm-class node, the TSMC N4P, on which the company builds everything from its current "Strix Point" mobile processors to the "Zen 5" CCDs. It turns out that AMD has other plans, and is exploring a 4 nm-class node by Samsung.
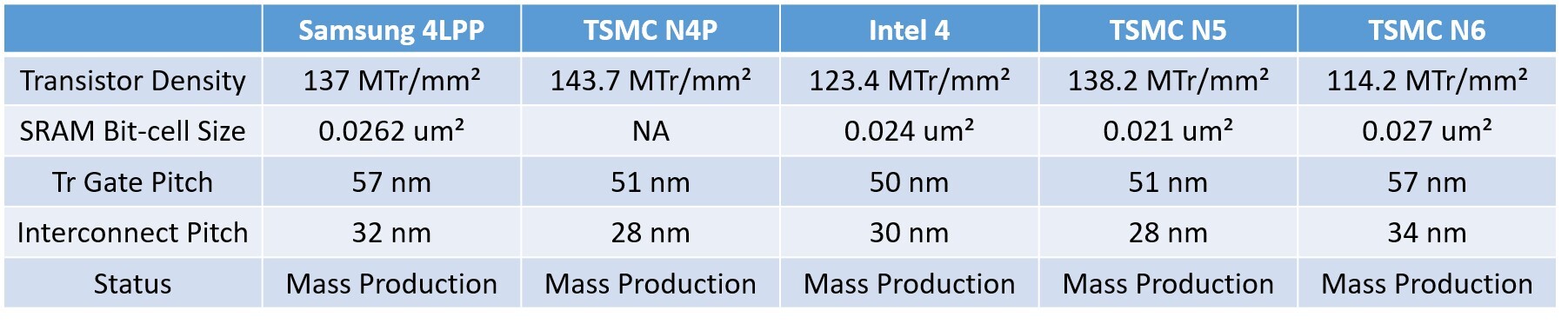
This node is very likely the Samsung 4LPP, also known as the SF4, which has been in mass-production since 2022. The table below shows how the SF4 compares with TSMC N4P and Intel 4, where it is shown striking a balance between the two. We have also added values for the TSMC N5 node from which the N4P is derived from, and you can see that the SF4 offers comparable transistor density to the N5, and is a significant improvement in transistor density over the TSMC N6, which AMD uses for its current generation of sIOD and cIOD. The new 4 nm node will allow AMD to reduce the TDP of the I/O die, implement a new power management solution, and more importantly, the need for a new I/O die is driven by the need for updated memory controllers that support higher DDR5 speeds and compatibility with new kinds of DIMMs, such as CUDIMMs, RDIMMs with RCDs, etc.
This node is very likely the Samsung 4LPP, also known as the SF4, which has been in mass-production since 2022. The table below shows how the SF4 compares with TSMC N4P and Intel 4, where it is shown striking a balance between the two. We have also added values for the TSMC N5 node from which the N4P is derived from, and you can see that the SF4 offers comparable transistor density to the N5, and is a significant improvement in transistor density over the TSMC N6, which AMD uses for its current generation of sIOD and cIOD. The new 4 nm node will allow AMD to reduce the TDP of the I/O die, implement a new power management solution, and more importantly, the need for a new I/O die is driven by the need for updated memory controllers that support higher DDR5 speeds and compatibility with new kinds of DIMMs, such as CUDIMMs, RDIMMs with RCDs, etc.