Intel 18A Is Officially Ready for Customer Projects
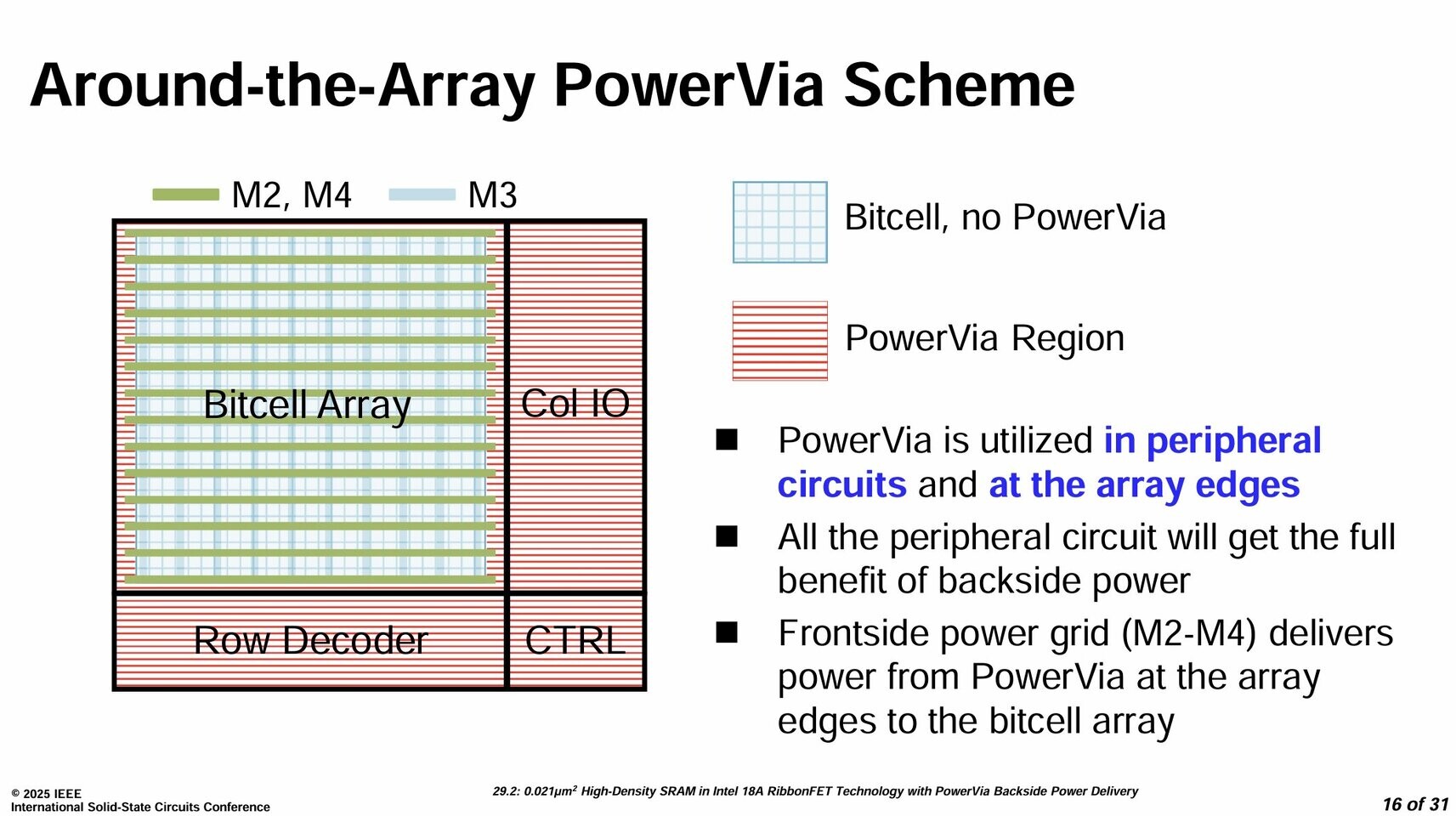
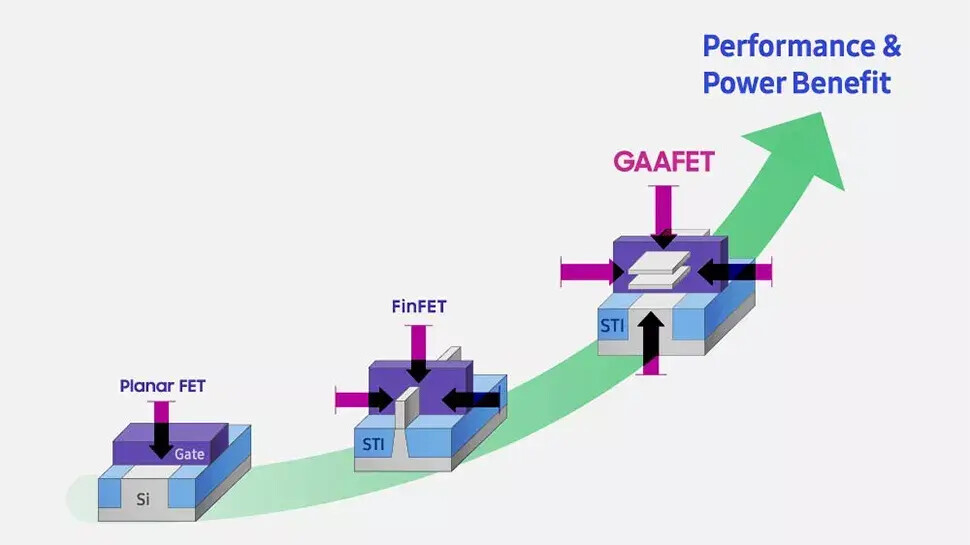
Intel has updated its 18A node website with the message, "Intel 18A is now ready for customer projects with the tape outs beginning in the first half of 2025: contact us for more information." The contact hyperlink includes an email where future customers can direct their questions to Intel. Designed as a turnaround node for Intel, 18A carries industry-leading features like SRAM density scaling comparable with TSMC's N2, 15% better performance per watt, and 30% better chip density vs. the Intel 3 process node used in Intel Xeon 6, as well as PowerVia backside-power delivery to increase transistor density.
Other features like RibbonFET are the first to replace FinFET transistors, making gate leakage a tighter control. Interestingly, Intel's first products to use the 18A node are client CPUs "Panther Lake" and "Clearwater Forest" Xeon CPUs for data centers. External Intel Foundry customers using the 18A node include Amazon's AWS, Microsoft for its internal silicon for Azure, and Broadcom exploring 18A-based designs. The process of gaining customers for advanced manufacturing is complex, as many existing Samsung/TSMC customers are not risking their capacity and contracts with established advanced silicon makers. However, if Intel's first few customers prove successful, many others could flock over to Intel's fabs as geopolitical tensions are questioning whether the current models of the semiconductor supply chain are feasible in the future. If US companies and startups decide to move with Intel for their chip manufacturing, Intel could experience a complete recovery.
Other features like RibbonFET are the first to replace FinFET transistors, making gate leakage a tighter control. Interestingly, Intel's first products to use the 18A node are client CPUs "Panther Lake" and "Clearwater Forest" Xeon CPUs for data centers. External Intel Foundry customers using the 18A node include Amazon's AWS, Microsoft for its internal silicon for Azure, and Broadcom exploring 18A-based designs. The process of gaining customers for advanced manufacturing is complex, as many existing Samsung/TSMC customers are not risking their capacity and contracts with established advanced silicon makers. However, if Intel's first few customers prove successful, many others could flock over to Intel's fabs as geopolitical tensions are questioning whether the current models of the semiconductor supply chain are feasible in the future. If US companies and startups decide to move with Intel for their chip manufacturing, Intel could experience a complete recovery.