NVIDIA's v580 Driver Branch Ends Support for Maxwell, Pascal, and Volta GPUs
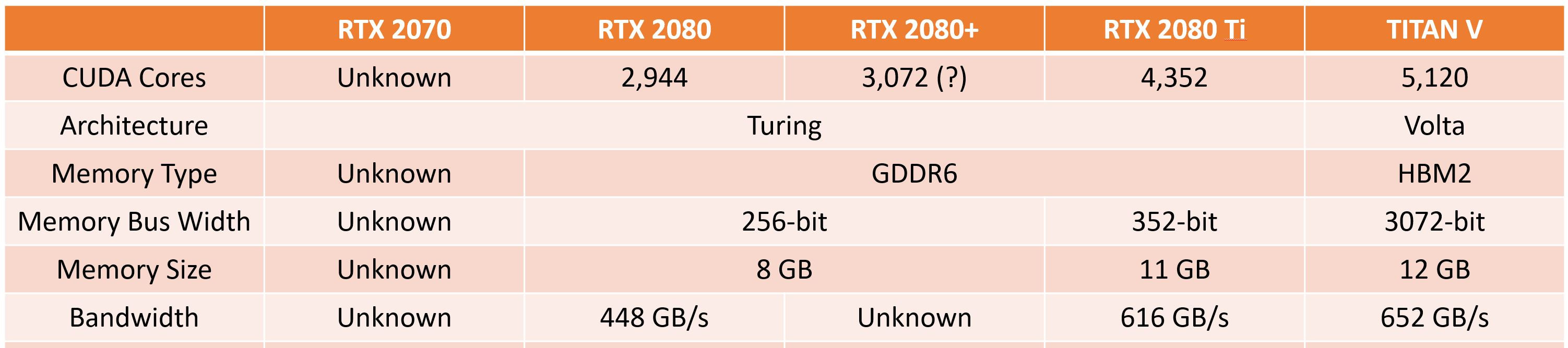
NVIDIA has confirmed that its upcoming 580 driver series will be the final release to offer official updates for three of its older GPU architectures. In a recent update to its UNIX graphics deprecation schedule, the company noted that once version 580 ships, Maxwell-, Pascal-, and Volta-based products will no longer receive new drivers or patches. Although this announcement originates from NVIDIA's UNIX documentation, the unified driver codebase means Windows users will face the same cutoff. Owners of Maxwell-era GeForce GTX 700 and GTX 900 cards, Pascal's GeForce GTX 10 lineup, and the consumer-focused Volta TITAN V can expect their last set of performance optimizations and security fixes in the 580 branch.
NVIDIA further explains that ending support for these legacy chips allows its engineering teams to focus on newer hardware platforms. For example, Turing-based GeForce GTX 16 series cards will continue to receive updates beyond driver v580, ensuring gamers can benefit from the latest optimizations and stability improvements even on older platforms. First introduced between 2014 and 2017, Maxwell, Pascal, and Volta GPUs will have enjoyed eight to eleven years of official maintenance, among the longest support windows in the industry. While existing driver installations will remain operational, NVIDIA recommends that users who depend on these older cards begin planning upgrades to maintain full compatibility and access new features. At the time of this announcement, the public driver sits at version 576.80, and NVIDIA has not yet set a firm release date for the 580 series, leaving affected users a window of several months before support officially ends.
NVIDIA further explains that ending support for these legacy chips allows its engineering teams to focus on newer hardware platforms. For example, Turing-based GeForce GTX 16 series cards will continue to receive updates beyond driver v580, ensuring gamers can benefit from the latest optimizations and stability improvements even on older platforms. First introduced between 2014 and 2017, Maxwell, Pascal, and Volta GPUs will have enjoyed eight to eleven years of official maintenance, among the longest support windows in the industry. While existing driver installations will remain operational, NVIDIA recommends that users who depend on these older cards begin planning upgrades to maintain full compatibility and access new features. At the time of this announcement, the public driver sits at version 576.80, and NVIDIA has not yet set a firm release date for the 580 series, leaving affected users a window of several months before support officially ends.