Monday, November 12th 2018

AMD "Zen 2" IPC 29 Percent Higher than "Zen"
AMD reportedly put out its IPC (instructions per clock) performance guidance for its upcoming "Zen 2" micro-architecture in a version of its Next Horizon investor meeting, and the numbers are staggering. The next-generation CPU architecture provides a massive 29 percent IPC uplift over the original "Zen" architecture. While not developed for the enterprise segment, the stopgap "Zen+" architecture brought about 3-5 percent IPC uplifts over "Zen" on the backs of faster on-die caches and improved Precision Boost algorithms. "Zen 2" is being developed for the 7 nm silicon fabrication process, and on the "Rome" MCM, is part of the 8-core chiplets that aren't subdivided into CCX (8 cores per CCX).
According to Expreview, AMD conducted DKERN + RSA test for integer and floating point units, to arrive at a performance index of 4.53, compared to 3.5 of first-generation Zen, which is a 29.4 percent IPC uplift (loosely interchangeable with single-core performance). "Zen 2" goes a step beyond "Zen+," with its designers turning their attention to critical components that contribute significantly toward IPC - the core's front-end, and the number-crunching machinery, FPU. The front-end of "Zen" and "Zen+" cores are believed to be refinements of previous-generation architectures such as "Excavator." Zen 2 gets a brand-new front-end that's better optimized to distribute and collect workloads between the various on-die components of the core. The number-crunching machinery gets bolstered by 256-bit FPUs, and generally wider execution pipelines and windows. These come together yielding the IPC uplift. "Zen 2" will get its first commercial outing with AMD's 2nd generation EPYC "Rome" 64-core enterprise processors.

Update Nov 14: AMD has issued the following statement regarding these claims.
Source:
Expreview
According to Expreview, AMD conducted DKERN + RSA test for integer and floating point units, to arrive at a performance index of 4.53, compared to 3.5 of first-generation Zen, which is a 29.4 percent IPC uplift (loosely interchangeable with single-core performance). "Zen 2" goes a step beyond "Zen+," with its designers turning their attention to critical components that contribute significantly toward IPC - the core's front-end, and the number-crunching machinery, FPU. The front-end of "Zen" and "Zen+" cores are believed to be refinements of previous-generation architectures such as "Excavator." Zen 2 gets a brand-new front-end that's better optimized to distribute and collect workloads between the various on-die components of the core. The number-crunching machinery gets bolstered by 256-bit FPUs, and generally wider execution pipelines and windows. These come together yielding the IPC uplift. "Zen 2" will get its first commercial outing with AMD's 2nd generation EPYC "Rome" 64-core enterprise processors.

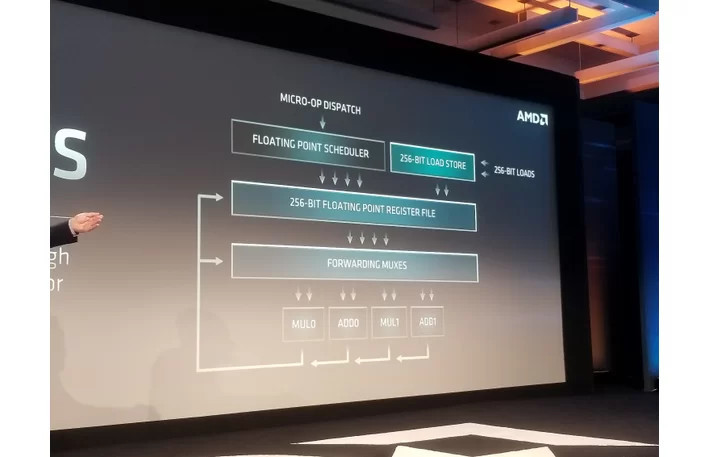
As we demonstrated at our Next Horizon event last week, our next-generation AMD EPYC server processor based on the new 'Zen 2' core delivers significant performance improvements as a result of both architectural advances and 7nm process technology. Some news media interpreted a 'Zen 2' comment in the press release footnotes to be a specific IPC uplift claim. The data in the footnote represented the performance improvement in a microbenchmark for a specific financial services workload which benefits from both integer and floating point performance improvements and is not intended to quantify the IPC increase a user should expect to see across a wide range of applications. We will provide additional details on 'Zen 2' IPC improvements, and more importantly how the combination of our next-generation architecture and advanced 7nm process technology deliver more performance per socket, when the products launch.
162 Comments on AMD "Zen 2" IPC 29 Percent Higher than "Zen"
It used to be easy to say this CPU is better than that CPU when CPUs had a single core. It's become more complicated ever since.
2 - Intel wants to claim it can be the fastest gaming CPU while being 95W TDP. That's simply not true. It's 95W, or it's fast. One or the other.
It's not a 95W part at the same time as being the fastest gaming CPU.
It's not the fastest gaming CPU at 95W.
Why are you so insistent on defending their clear attempt to advertise a dichotomous product in a misleading way? What do you get out of refusing to admit that Intel's CPU draws as much power as it actually does?
EDIT: It was posted a few days ago so perfect timing for this thread.
About the temps, by increasing IPC Intel could reduce clocks and still have higher performance with lower temps.I said single threaded or IPC not because I think they are the same, but because Intel beats AMD in both.
Lisa Su said that work on Zen2 began 4 years back, sometime after that they would've realized that their vision could only be fulfilled on 7nm. Like wise for Intel they've been working on Icelake for 4~6 years & even if one assumes it could theoretically be backported to 14nm+++ that simply wouldn't work without major compromises to the final design. Just an FYI retail chips are rumored to feature AVX512, which is simply not possible on this node. That IPC gain includes a hefty one time benefit from AVX512.
The real story is told by IPC advances within the Core architecture and those are so massive, they are responsible for the lead AMD is still working to catch up on. Intel's main issue with Core is that they pulled out all the stops already with Sandy Bridge, and it was so strong, it remains relevant to this day. This is also why I among others say that Core has reached its peak and it needs radical changes to remain relevant. Its the same with GCN. Everything shows that it has been stretched to the max.
The story with Bulldozer is different and its remarkably similar to how they approach GPU up to today: as an iterative work in progress. You basically buy something that isn't fully optimized, and then you get to say 'ooh aah' every time AMD releases an update because performance increased. Unfortunately when the competition does go all the way, that means you end up with inferior product where optimization always trails reality.
Intel could – and I want that being understood as my forecast for their oh so awesome and totally revealing event on December 11th (hint: It won't be …) – they could help themselves quite a bit, if they just blatantly copy AMD's Fineglue™. Whereas I strongly guess, that they will do exactly this;
How I'm envision Intel's near future roud-map:
Prediction:
For the consumer-market, Intel copies AMD's (UMI's?) HBM-alike MCP-approach and starts to manufature CPUs being glued-together (hurr, hurr) from complete and rather unchanged unaltered common CPU-Dies using
QPIUPI, like two dual-core and quad-core Dies on a single chip – pretty much what they're about to do now with Cascade Lake in the server-space. So a rather common approach on unaltered MCP-level, just whole Dies combined unaltered at PCB-level.After that, Intel in their second coming copies AMD on technology-level (once again) in the direction of a 'clustered CPU' and starts with a modular assembly using chiplets of different manufatured node-sizes too, connected (
optimallyhopefully) via their EMIB. That way they would be able to manufacture tiny core-chiplets which shall be reduced to e.g. only 4 cores per chiplet (or just 2 cores or even a single one). Such embodied pure-core chiplet or core-complex would be so tiny, that Intel could fab such chiplets hopefully even on theirbrokentotally working on track™ 10nm node.That way, they wouldn't have to give up their ardently loved black hole called iGPU too (or how I like to call it: »Adventures of The Mighty Blue Electron facing Competition: The Road towards Iris-Graphics«), while still bringing it in as a dedicated modular chiplet on e.g.
22nm14nm.So, tiny dedicated and independent core-complexes for the CPU-core part – let's call them CCi for now (Core Complex Independency) – while bringing in the rest of it on 14nm or even 22nm (given that their 28 nm process stopgap isn't still running yet …). All that as a modular Cluster-CPU
putglued-together on actual Die-level as chiplets.But seriously, ... that way, a) Intel could save their own ass over the time-span while they literally has nothing left (to lose) until they come up with
theira hopefully newly revamped architecture, b) use and thus save their disastrous 10nm-fiasco (without the obvious need to just write it off [since for anything more than a Dual-core that node's yields are evidently out for the count]) and they c) even would come down from their insanely expensive monolithic Die-approach while even saving huge manufacturing- and processing-costs and thus d) increase profits.Sounds quite like a plan, doesn't it?! Actually like a
realepic masterplan I must say! I wonder why no-one else hasn't come up with such brilliancy yet?! … oh, wait!Well, one can dream, can I?
Anyway, I'm thrilled!
Smartcom
Skylake-X has AVX512 in 14 nm, so mainstream AVX512 in 14 nm can be possible.
Maybe people have been unaware till now, but this a trick that has been employed for a while by both Intel and AMD. The only thing that changed is Intel decided to put fewer numbers on the box. The numbers were apparently easily accessible to the people that wrote that article, so it's not like Intel keeps them secret.My apology, I didn't know you had the power to decide what's reasonable and what's not reasonable around here.I didn't realize you know what Intel wants to claim either.
To me this is extremely simple: people are stupid, you put more than one number on the box, they get confused. Intel realized that and decided not to put several TDPs on the box anymore.
For those genuinely curious about the platform and how to properly tweak it, all the info is right here: www.intel.com/content/www/us/en/products/docs/processors/core/8th-gen-core-family-datasheet-vol-1.html (search for PL2)
Edit: @bug That TDP-classification of just 95W still is just deceptive …
Though that was without question the whole intention from the get-go when they started rating it that way, based on base-clocks.
It was an (working) approach to make look their chips more energy-efficiency while the efficiency of those chips didn't really changed at all.
Smartcom
"Over the last decade, while the use of the term TDP has not changed much, the way that its processors use a power budget has. The recent advent of six-core and eight-core consumer processors going north of 4.0 GHz means that we are seeing processors, with a heavy workload, go beyond that TDP value. In the past, we would see quad-core processors have a rating of 95W but only use 50W, even at full load with turbo applied. As we add on the cores, without changing the TDP on the box, something has to give. "
There has been a change from what was before.
So no ICL, if it has AVX512, is not possible on any variant of 14nm.
Keep in mind cTDP is not new. It has been with us since 2012 (actually introduced by AMD, not Intel), but we've been used to seeing it used the other way around, in laptops.
Using disabled 8-core dice for low-end 2c4t 15W mobile parts with near zero margin for $400 laptops will not fly, no matter what. If yields on 7nm are bad enough for this to be a viable solution, that's a significant problem, and if yields are good, they'd need to disable working silicon to sell as <$100 mobile parts with next-to-no margin. In the millions, as that's the numbers those markets operate in. That billion dollars would suddenly become inconsequential as they'd be wasting higher-grade dice to sell as low-end crap for no profit. It doesn't take much of this for a smaller, better suited design to become the cheaper solution.
"So where do we go from here? I'd argue that Intel needs to put two power numbers on the box:
- TDP (Peak) for PL2
- TDP (Sustained) for PL1
This way Intel and other can rationalise a high peak power consumption (mostly), as well as the base frequency response that is guaranteed."Read the Anandtech article and then come back and see how you think about what's going on with Intel TDP numbers.www.anandtech.com/show/13544/why-intel-processors-draw-more-power-than-expected-tdp-turbo
Again, I see no trickery at work. Just a company finding a way to squeeze more cores on a production node they were planning to leave behind at least two years ago. Both Nvidia and AMD had to do something similar when TSMC failed with their 22nm node and everybody got stuck with 28nm for a couple more years than originally planned.Well, I don't see it as deceptive, because 95W is all a board manufacturer has to support.
But when you start using words like "without question" to make your point, you're kind of preventing us further discussing this. Have a nice day.
The test used, AFAICT, was a concurrent discrete kernel workload - running on an unknown dataset of an unknown size - and an RSA cryptography workload - unknown version, complexity, optimizations, etc...
The IPC values gives us some clue about how this was run.
First, dkern() frequently runs almost entirely within the FPU and performance is more a factor of branch prediction and getting results from the FPU back into an ALU branch pipeline. It's actually a pretty decent generic test for the front end and FPU - not coincidentally the only two things AMD really talked about in regards to core improvements.
RSA is a heavy integer and floating point load. It does pow() (exponents) and gcd() (greatest common denominator) operations, integer comparisons, type casts, and all manner of operation that usually hammers ALUs and FPUs in turn (rather than concurrently). It uses different ALUs than dkern() and mostly can benefit from the same types of improvements - as well as the CPU recognizing, for example, the gcd() code pattern and optimizing it on the fly on multiple ALUs concurrently.
Together, this CPU was being hammered during testing by two workloads that do quite well with instruction level parallelism (ILP) - the magic behind IPC with x86.
We can't read anything more from these results other than Zen 2 is ~30% faster when doing mixed integer and floating point workloads.
However, that particular scenario is actually very common. For games, specifically, we should see a large jump - mixed integer, branch, and floating point work loads with significant cross communication is exactly what the cores see in heavy gaming loads - Intel has won here because they have a unified scheduler, making it easier to get FPU results back to dependent instructions which will execute on an ALU (which might even be the same port on Intel...), it looks like AMD has aimed for superiority on this front.