Monday, May 4th 2020

Intel's Alder Lake Processors Could use Foveros 3D Stacking and Feature 16 Cores
Intel is preparing lots of interesting designs for the future and it is slowly shaping their vision for the next generation of computing devices. Following the big.LITTLE design principle of Arm, Intel decided to try and build its version using x86-64 cores instead of Arm ones, called Lakefield. And we already have some information about the new Alder Lake CPUs based on Lakefield design that are set to be released in the future. Thanks to a report from Chrome Unboxed, who found the patches submitted to Chromium open-source browser, used as a base for many browsers like Google Chrome and new Microsoft Edge, there is a piece of potential information that suggests Alder Lake CPUs could arrive very soon.
Rumored to feature up to 16 cores, Alder Lake CPUs could present an x86 iteration of the big.LITTLE design, where one pairs eight "big" and eight "small" cores that are activated according to increased or decreased performance requirements, thus bringing the best of both worlds - power efficiency and performance. This design would be present on Intel's 3D packaging technology called Foveros. The Alder Lake CPU support patch was added on April 27th to the Chrome OS repository, which would indicate that Intel will be pushing these CPUs out relatively quickly. The commit message titled "add support for ADL gpiochip" contained the following: "On Alderlake platform, the pinctrl (gpiochip) driver label is "INTC105x:00", hence declare it properly." The Chrome Unboxed speculates that Alder Lake could come out in mid or late 2021, depending on how fast Intel could supply OEMs with enough volume.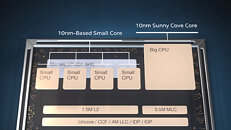
Sources:
@chiakokhua (Twitter), Chrome Unboxed
Rumored to feature up to 16 cores, Alder Lake CPUs could present an x86 iteration of the big.LITTLE design, where one pairs eight "big" and eight "small" cores that are activated according to increased or decreased performance requirements, thus bringing the best of both worlds - power efficiency and performance. This design would be present on Intel's 3D packaging technology called Foveros. The Alder Lake CPU support patch was added on April 27th to the Chrome OS repository, which would indicate that Intel will be pushing these CPUs out relatively quickly. The commit message titled "add support for ADL gpiochip" contained the following: "On Alderlake platform, the pinctrl (gpiochip) driver label is "INTC105x:00", hence declare it properly." The Chrome Unboxed speculates that Alder Lake could come out in mid or late 2021, depending on how fast Intel could supply OEMs with enough volume.

40 Comments on Intel's Alder Lake Processors Could use Foveros 3D Stacking and Feature 16 Cores
Big.little is a crude way of doing it, effectively throwing silicon at the problem. The benefit is that it is simpler to set up, the negative is that the courser the powergating, the slower the responsiveness as the time taken to 'turn on' and initialise the powered up processor element increases.Agree, it does nothing for power use under load. Like I said, this is more coming out of Intel marketing requirements than actual better end-user experience. It allows Intel to spruik bullsh*t 'up-to XX hours battery life' metrics (bullsh*t because no one idles their laptop for 12 hours straight) and 'Moar cores', even if those extra cores perform like potatoes. My point was more that the principles of big.little as a power saving measure are sound, but also crude, and I would expect someone with the R&D budget of Intel to implement something more sophisticated than rehashing a 9 year old idea from ARM.
1. Clustered switching - the described by you - either big cores or small cores and never at the same time;
2. In-kernel switcher - when a big and a small cores are coupled into pairs, so with 8 + 8 you would have something like 8 big cores + hyper-threading enabled;
and the third:
3. Heterogenous multi-processing (global scheduling):en.wikipedia.org/wiki/ARM_big.LITTLE#cite_note-14
en.wikipedia.org/wiki/ARM_big.LITTLE
The thing also which should be considered is that you have frequency wall on the 14nm process, so no matter the approach, more performance would not be possible.
And the whole approach will still be inferior to Zen 3 and Zen 4, especially with 16 big cores (or double) with SMT.
Power saving systems means to clock the cores between 0 MHz and 4800 MHz, and allow the cores to execute tasks even at 50 or 25 MHz.
This "allowing a Skylake core to morph into a Goldmont core" isn't happening. Intel moved to a considerably larger core with Sunny Cove (and if the rumors are true, even bigger in Willow Cove) in order to leverage that performance over traditional Core, to stay competitive. All these Alder Lake rumors reek of Intel engineers finally giving up on trying to optimize this larger Core for efficiency because their 10nm+ process still isn't worth a damn and 7nm is nowhere in sight, and instead turning to shitty Atom for the lower end of the power spectrum.
Intel can forget trying to turn off half a core, running cores at 25MHz, or juggling Atom and Core on the same substrate, if they can't even get their own Speed Shift technology down to where it rivals AMD's CPPC2. That's a prerequisite to all this nonsense. And if they do in fact perfect that concept, that would just enable Tiger Lake to perform in an adaptive manner as Renoir does, so then what's the point of using Goldmont? Mainstream consumers want an thin and light notebook that draws power like it's not even on when at idle, but ramps up to provide the requisite performance at a moment's notice. What Renoir is capable of, hits that nail right on the head.
And then there's the Windows scheduler, the worst cockblock of all.
I could be wrong but I don't think all cores will be usable at he same time.
A lot of the obvious stuff has already been done.
I don't see neither the Task Manager nor a third-party program like Core Temp to report anything lower than 1496 MHz on my APU ?
Renoir is the benchmark which we should compare everything else with.
Actually, laptops have much larger batteries than phones and despite this, the phones can last for weeks in standby, while poor laptops in the best case can last half a day in standby.
1 big Sunny Cove core + 4 small Tremont cores.
This is the so called non-symmetric grouping heterogeneous multi-core of BIG.little cores.
en.wikichip.org/wiki/intel/microarchitectures/lakefield