Tuesday, September 29th 2020

First Signs of AMD Zen 3 "Vermeer" CPUs Surface, Ryzen 7 5800X Tested
AMD is preparing to launch the new iteration of desktop CPUs based on the latest Zen 3 core, codenamed Vermeer. On October 8th, AMD will hold the presentation and again deliver the latest technological advancements to its desktop platform. The latest generation of CPUs will be branded as a part of 5000 series, bypassing the 4000 series naming scheme which should follow, given that the prior generation was labeled as 3000 series of processors. Nonetheless, AMD is going to bring a new Zen 3 core with its processors, which should bring modest IPC gains. It will be manufactured on TSMC's 7 nm+ manufacturing node, which offers a further improvement to power efficiency and transistor density.
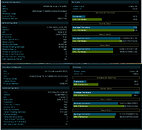
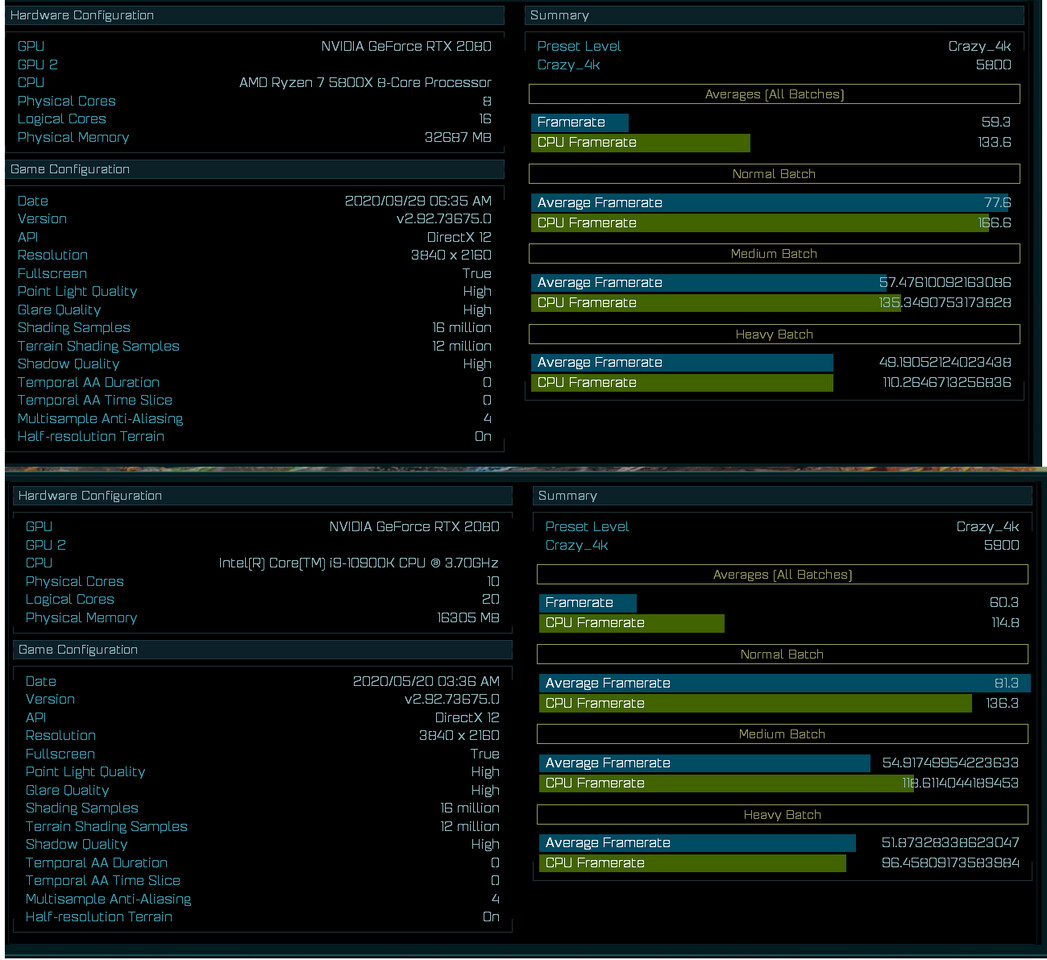
Today, we have gotten the first benchmark of AMD's upcoming Ryzen 7 5800X CPU. Thanks to the popular hardware leaker, TUP APISAK, we have the first benchmark of the new Vermeer processor, compared to Intel's latest and greatest - Core i9-10900K. The AMD processor is an eight-core, sixteen threaded model compared to the 10C/20T Intel processor. While we do not know the final clocks of the AMD CPU, we could assume that the engineering sample was used and we could see an even higher performance. Below you can see the performance of the CPU and how it compares to Intel. By the numbers shown, we can expect AMD to possibly be a new gaming king, as the numbers are very close to Intel. The average batch result for the Ryzen 7 5800X was 59.3 FPS and when it comes to CPU frames it managed to score 133.6 FPS. Intel's best managed to average 60.3 FPS and 114.8 FPS from the CPU framerates. Both systems were tested with NVIDIA's GeForce RTX 2080 GPUs.
Source:
@TUM_APISAK (Twitter)
Today, we have gotten the first benchmark of AMD's upcoming Ryzen 7 5800X CPU. Thanks to the popular hardware leaker, TUP APISAK, we have the first benchmark of the new Vermeer processor, compared to Intel's latest and greatest - Core i9-10900K. The AMD processor is an eight-core, sixteen threaded model compared to the 10C/20T Intel processor. While we do not know the final clocks of the AMD CPU, we could assume that the engineering sample was used and we could see an even higher performance. Below you can see the performance of the CPU and how it compares to Intel. By the numbers shown, we can expect AMD to possibly be a new gaming king, as the numbers are very close to Intel. The average batch result for the Ryzen 7 5800X was 59.3 FPS and when it comes to CPU frames it managed to score 133.6 FPS. Intel's best managed to average 60.3 FPS and 114.8 FPS from the CPU framerates. Both systems were tested with NVIDIA's GeForce RTX 2080 GPUs.

82 Comments on First Signs of AMD Zen 3 "Vermeer" CPUs Surface, Ryzen 7 5800X Tested
Then you have that the 10900k only lost in synthetic 'cpu framerate', it won in 2 out of 3 on actual framerate (which is what you'd actually see)...
This really looks more like a planned marketing stunt than an objective benchmark to me. We will know in a few weeks either way.
This guy made different workloads and run them on a Phenom and i7 8th gen, even though the phenom is so ol it's still faster in some:
For example, Cinebench.
hothardware.com/news/amd-ryzen-7-5800x-zen-3-benchmark-leak-parallel-single-threading
does anyone else think that single core score is FAR to low ?
Looking beyond the surface and clickbait article titles of this "leak" - if Zen 3 is so good, why is an AMD co-sponsored title being used at 4k for pre-release hype and still losing in actual FPS 2/3 of the time? And why are both recent leaks - one on 5700U a week ago and now this one on 5800X - for that *same* AMD sponsored title which very few play regularly? Why not use something a bit more mainstream at settings that don't go GPU limited? Hmmm.....
I mentioned the concept of it in the Intel bigLITTLE TPU thread not that far back you can basically manipulate clock skew or cycle duties in a clever manner in theory to get more performance by manipulating it in a similar fashion to what was done with by MOS Technology with the SID chip for the arpeggio's to simulate playing chords with polyphony it was a clever hardware trick at the time. It seems far fetched and somewhat unimaginable to actually be applied, but innovation always is you have to think outside the box or you'll always been stuck in a box.
This is a quadruple LFO what is allegedly being done is twin LFO if you look at the intersection points that's half a cycle duty rising and falling voltages/frequencies. If you look at the blue and green or yellow and purple they intersect perfectly. What's being done is a switching at the intersection cross section so you've got two valley peaks closer together and the base of the mountain so to speak isn't as far downward. That's assuming this is in fact being done and put into practice by AMD. I see it within the oscilloscope of possibilities for certain. That's basically what DDR memory did in practice. Big question is if they can pull it off within the dynamic complexity of software. Then again why can't they!!? Can't see what they can't divert it like a rail road track at that crossroad intersection point. That nets you a roughly 50% performance gain with 4 chips the valley dips would be reduce more and the peaks would happen more routinely and you'd end up with 100% more performance I think that's what DDR5 is suppose to do actually on the data rate hence the phrase quad data rate.
Thinking about it further I really don't see a problem with the I/O die managing that type of load switching in real time quickly and the data would already be present in the CPU memory it's not like it gets flushed instantly. Yeah maybe it could become a bit of a materialized reality. If not now certainly later. I have to think AMD will incorporate a I/O for the GPU soon as well if they want to pursue multi-chip GPU's.
If this were a car, what you are doing would be like calculating 0-60 time based on engine HP and car weight, while ignoring *actual* 0-60 time. No one does that. In real FPS Ryzen 3800X loses all 3 and 5800X loses 2 out of 3.
Hell some cars are so fast they don't even do 0-60 mph anymore they do 0-100mph.How is it AMD glorified if intel is winning ?
Where do you see 5900x ?, this 5800X 8 core 16 thread vs 10 core 20 thread.
The game is suppose to be really good at using multi thread it even shows the Threadripper 3960x is quite good on it
When doing real optimization of code, it's common to benchmark whole algorithms or larger pieces of code to see the real world difference of different approaches. It's very rare that you'll find a larger piece of code that performs much better on Skylake and a competing alternative which performs much better on let's say Zen 2. Any difference that you'll find for single instructions will be less important than the overall improvements of the architecture. And it's not like there will be an "Intel optimization", Intel has changed the resource balancing for every new architecture, so has AMD.
Interestingly the sample code in that video scales poorly with many cores, but should be able to scale nearly linearly if the work queue is implemented smarter.Instruction level parallelism is already heavily used, there is no need to spread the ALUs, FPUs, etc. across several cores, the distance would make a synchronization nightmare. We should expect future architectures to continue to scale their superscalar abilities. But I don't doubt that someone will find a clever way to utilize "idle transistors" in some of these by manipulating clock cycles etc.
The problem with superscalar scaling is keeping execution units fed. Both Intel and AMD currently have four integer pipelines. Integer pipelines are cheap (both in transistors and power usage), so why not double or quadruple them? Because they would struggle to utilize them properly. Both of them have been increasing instruction windows with every generation to try to exploit more parallelism, and Intel's next gen Sapphire Rapids/Golde Cove is allegedly featuring a massive 800 entry instruction window (Skylake has 224, Sunny Cove 352 for comparison). And even with these massive CPU front-ends, execution units are generally under-utilized due to branch mispredictions and cache misses. Sooner or later the ISA needs to improve to help the CPU, which should be theoretically possible, as the compiler has much more context than is passed on through the x86 ISA, as well as eliminating more branching.
The above is the easy case. There's lots of pattern matching and heuristics that help the pipelines figure out if foo() needs to be shoved into the pipelines, or if bar() needs to be shoved into the pipelines (while calculating blah() in parallel).
Now consider the following instead:
You simply can't "branch predict" the virtualFunctionCall() much better than what we're doing today. Today, there are ~4 or 5 histories stored into the Branch Target Buffer (BTB), so the most common 3 or 4 classes will have their virtualFunctionCall() successfully branch-predicted without much issue. There are also 3 levels of branch predictor pattern-matchers running in parallel, giving the CPU three different branch targets (L1 branch predictor is fastest but least accurate. L3 branch predictor is most accurate but almost the slowest: only slightly faster than a mispredicted branch).
This demonstrates the superiority of runtime information (if there's only 2 or 3 classes in the array[], the CPU will branch predict the virtualFunctionCall() pretty well). The compiler cannot make any assumptions about the contents of array.
---------
By the way: most "small branches" are compiled into CMOV sequences on x86, no branch at all.
--------------
The only things being done grossly different seem to be the GPU architectures, which favor no branch prediction at all, and instead just focus on wider-and-wider SMT to fill their pipelines (and non-uniform branches are very, very inefficient because of thread divergence. Uniform branches are efficient on both CPUs and GPUs, because CPUs will branch-predict a uniform branch while GPUs will not have any divergence). Throughput vs Latency strikes again: GPUs can optimize throughput but CPUs must optimize latency to be competitive.
I was thinking of branching logic inside a single scope, like a lot of ifs in a loop. Compilers already turn some of these into branchless alternatives, but I'm sure there is more potential here, especially if the ISA could express dependencies so the CPU could do things out of order more efficiently and hopefully some day limit the stalls in the CPU. As you know, with ever more superscalar CPUs, the relative cost of a cache miss or branch misprediction is growing.
Ideally code should be free of unnecessary branching, and there are a lot of clever tricks with and without AVX, which I believe we have discussed previously.
But about your virtual function calls. If your critical path is filled with virtual function calls and multiple levels of inheritance, you're pretty much screwed performance wise, no compiler will be able to untangle this at compile time. And in most cases (at least how most programmers use OOP), these function calls can't be statically analysed, inlined or dereferenced at compile time.
@ efikkan I kept hearing him talk about switching in that video. I remember somethings about that is why AMD multi threading always ended feeling more responsive then Intel. It was something about Hitting ALT tab in windows while gaming, it just seems to be quicker at odd stuff like that.
@dragontammer5877 There are some benches that show there is some bottleneck with zen 2. Everyone says it's it's infinity fabric. The best way to get around the Infinity fabric bottleneck would be to add another link. If's it's only one link, because sometimes you got that lowly 3300X getting up in-between things like the 3900x and 3950x. We know that is usually, because it's a single CCX. Then again If the 3900x is ahead that would put it down to it having a larger cache ratio to cores.
The cache misses defiantly are harsh when they happen, but wouldn't automatically cycle modulating the individual L1/L2/L3 caches in different chip dies through the I/O die get around that? Cycle between the ones available basically. Perhaps they only do it with larger L2/L3 cache's though I mean maybe it doesn't make enough practical sense with the L1 cache being so small and switch times and such. Perhaps in a future design at some level or another I don't know.
Something else on the I/O die doing modulation switching between cores or die's at the core level in particular they could it based on poll chips and which ever can precision boosts the highest select that one for the single thread performance then poll it again after a set period and select whichever core gave the best results again and keep doing that approach. Basically no matter what it could always try to select the highest boost speed to optimize the single thread performance. Perhaps it does that between cores and die's as well so if one gets a little hot let it cool off while making use of the coolest die though switching between those might be less intermittent.
Dependency management on today's CPUs and compilers is a well solved problem: "xor rax, rax" cuts a dependency, allocates a new register from the reorder buffer, and starts a parallel-calculation that takes advantage of super-scalar CPUs. Its a dirty hack, but it works, and it works surprisingly well. I'm not convinced that a new machine-code format (with more explicit dependency matching) is needed for speed.
I think the main advantage to a potential "dependency-graph representation" would be power-consumption and core-size. Code with more explicit dependencies encoded could have smaller decoders that use less power, leveraging information that the compiler already calculated (instead of re-calculating it from scratch, so to speak).
Modern ROBs are 200+ long already, meaning the CPU can search ~200 instructions looking for instruction-level parallelism. And apparently these reorder buffers are only going to get bigger (300+ for Icelake).