Wednesday, October 28th 2020

AMD Announces the Radeon RX 6000 Series: Performance that Restores Competitiveness
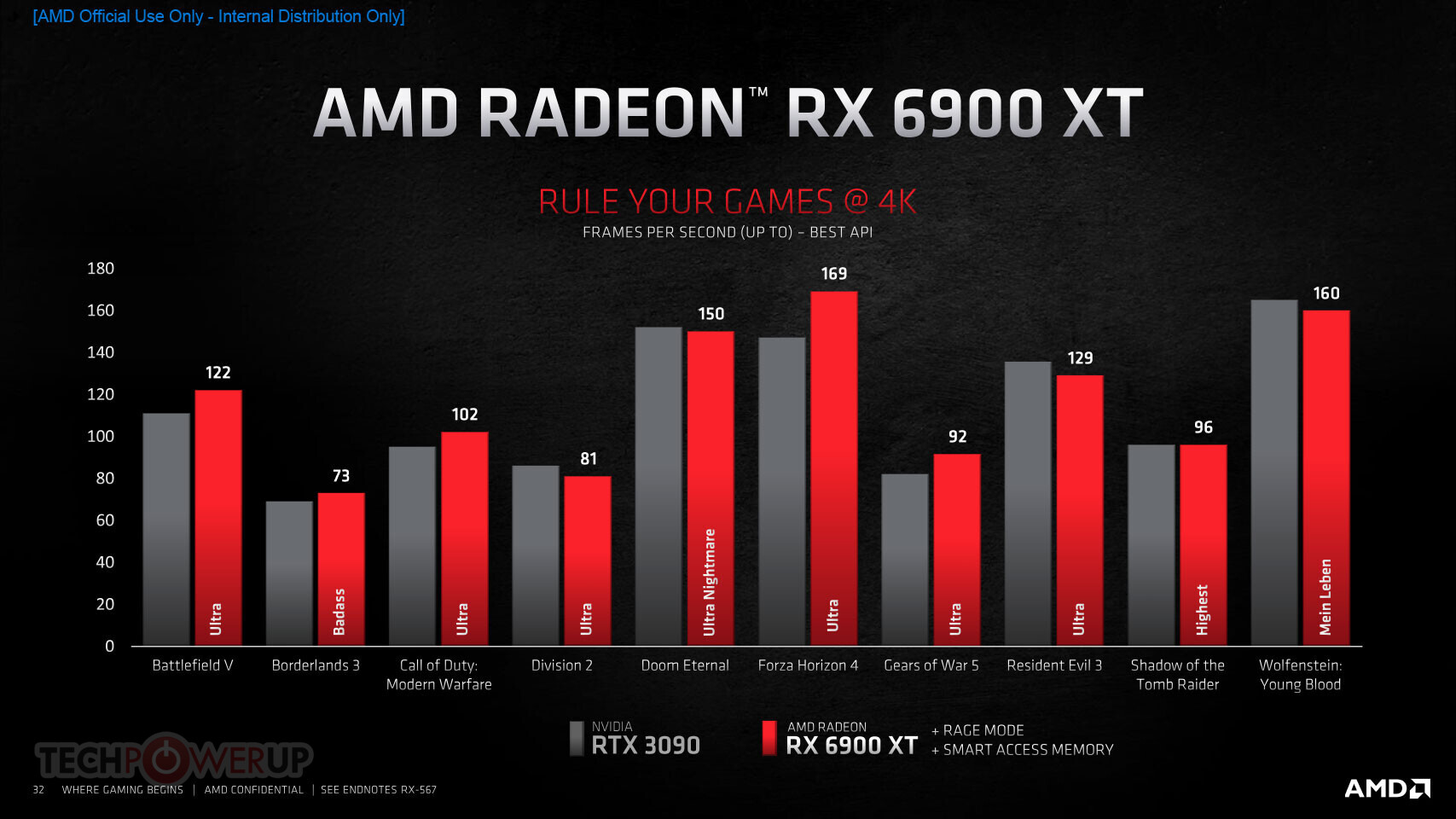
AMD (NASDAQ: AMD) today unveiled the AMD Radeon RX 6000 Series graphics cards, delivering powerhouse performance, incredibly life-like visuals, and must-have features that set a new standard for enthusiast-class PC gaming experiences. Representing the forefront of extreme engineering and design, the highly anticipated AMD Radeon RX 6000 Series includes the AMD Radeon RX 6800 and Radeon RX 6800 XT graphics cards, as well as the new flagship Radeon RX 6900 XT - the fastest AMD gaming graphics card ever developed.
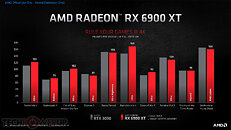
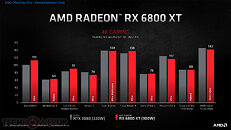
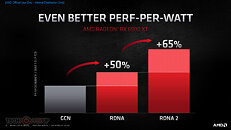
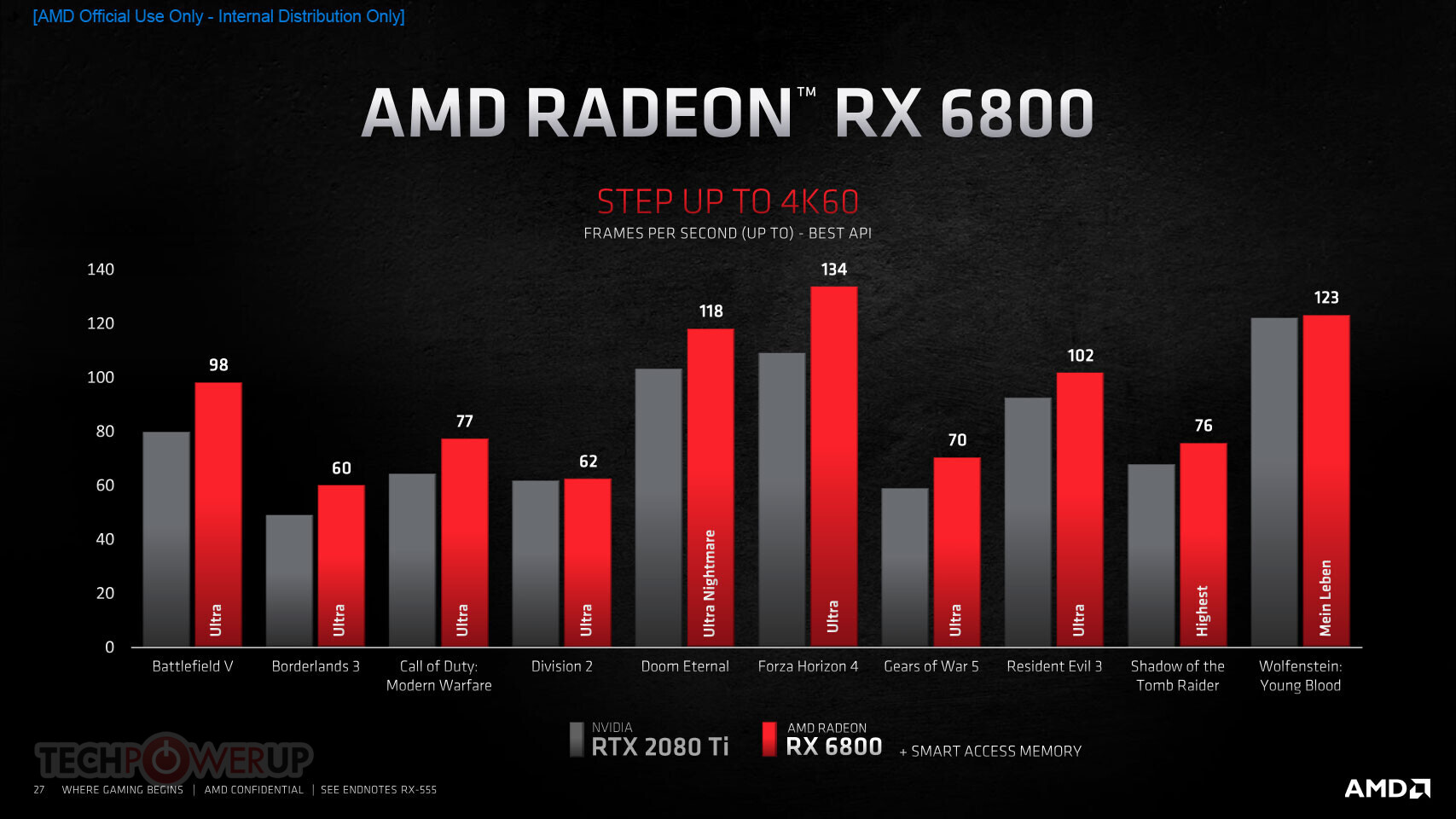
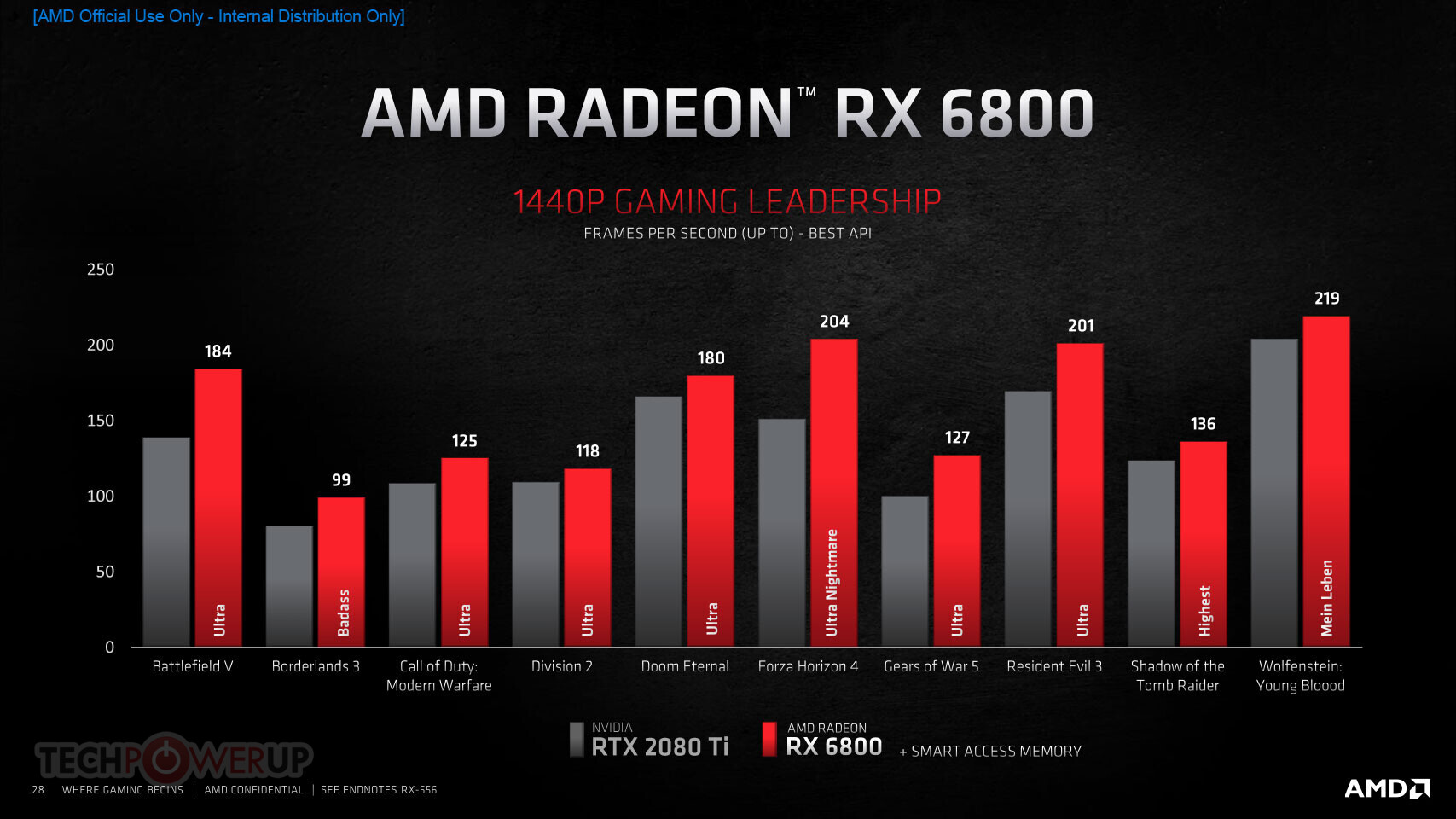
AMD Radeon RX 6000 Series graphics cards are built upon groundbreaking AMD RDNA 2 gaming architecture, a new foundation for next-generation consoles, PCs, laptops and mobile devices, designed to deliver the optimal combination of performance and power efficiency. AMD RDNA 2 gaming architecture provides up to 2X higher performance in select titles with the AMD Radeon RX 6900 XT graphics card compared to the AMD Radeon RX 5700 XT graphics card built on AMD RDNA architecture, and up to 54 percent more performance-per-watt when comparing the AMD Radeon RX 6800 XT graphics card to the AMD Radeon RX 5700 XT graphics card using the same 7 nm process technology.

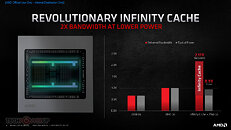
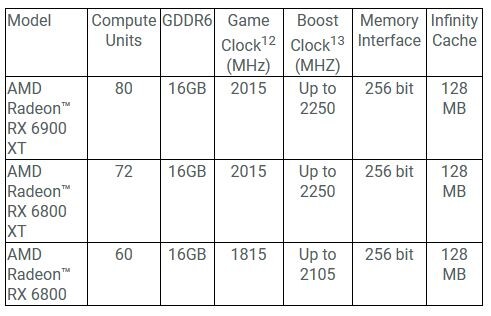
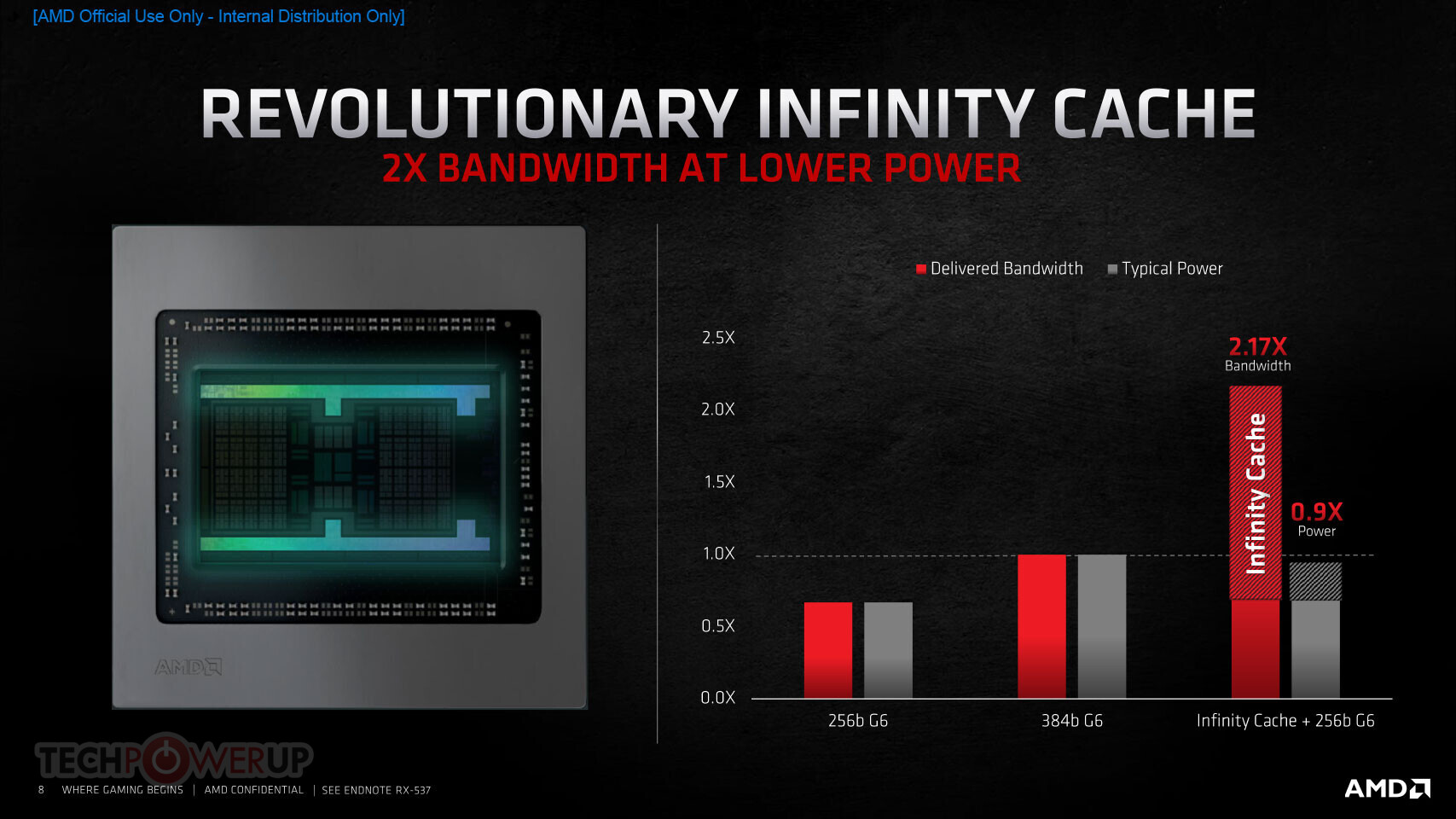
 AMD RDNA 2 offers a number of innovations, including applying advanced power saving techniques to high-performance compute units to improve energy efficiency by up to 30 percent per cycle per compute unit, and leveraging high-speed design methodologies to provide up to a 30 percent frequency boost at the same power level. It also includes new AMD Infinity Cache technology that offers up to 2.4X greater bandwidth-per-watt compared to GDDR6-only AMD RDNA -based architectural designs.
AMD RDNA 2 offers a number of innovations, including applying advanced power saving techniques to high-performance compute units to improve energy efficiency by up to 30 percent per cycle per compute unit, and leveraging high-speed design methodologies to provide up to a 30 percent frequency boost at the same power level. It also includes new AMD Infinity Cache technology that offers up to 2.4X greater bandwidth-per-watt compared to GDDR6-only AMD RDNA -based architectural designs.
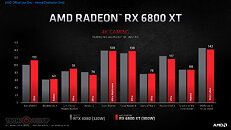
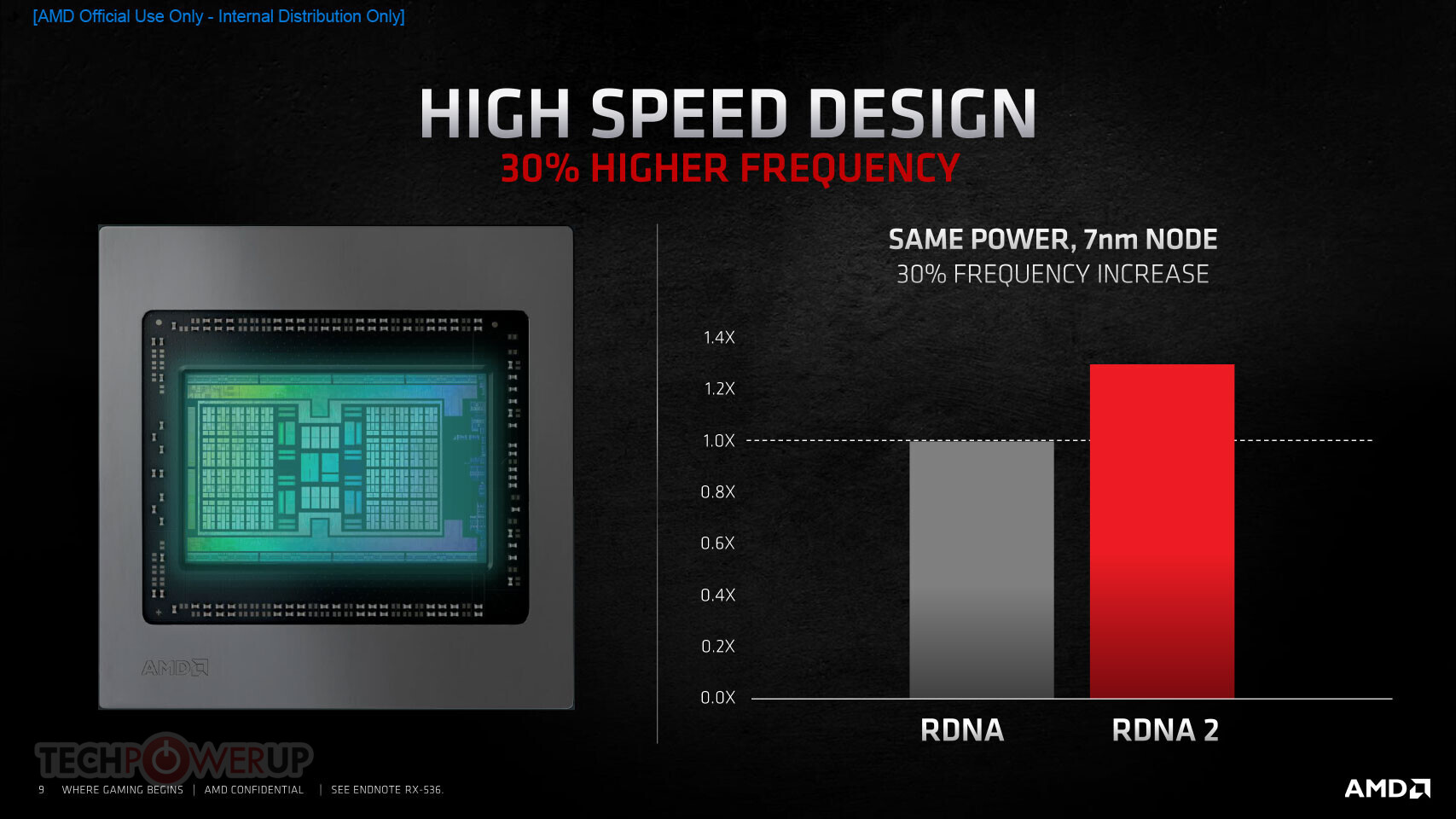
"Today's announcement is the culmination of years of R&D focused on bringing the best of AMD Radeon graphics to the enthusiast and ultra-enthusiast gaming markets, and represents a major evolution in PC gaming," said Scott Herkelman, corporate vice president and general manager, Graphics Business Unit at AMD. "The new AMD Radeon RX 6800, RX 6800 XT and RX 6900 XT graphics cards deliver world class 4K and 1440p performance in major AAA titles, new levels of immersion with breathtaking life-like visuals, and must-have features that provide the ultimate gaming experiences. I can't wait for gamers to get these incredible new graphics cards in their hands."
Powerhouse Performance, Vivid Visuals & Incredible Gaming Experiences
AMD Radeon RX 6000 Series graphics cards support high-bandwidth PCIe 4.0 technology and feature 16 GB of GDDR6 memory to power the most demanding 4K workloads today and in the future. Key features and capabilities include:
Powerhouse Performance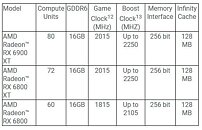 Robust Gaming Ecosystem and Partnerships
Robust Gaming Ecosystem and Partnerships
In the coming weeks, AMD will release a series of videos from its ISV partners showcasing the incredible gaming experiences enabled by AMD Radeon RX 6000 Series graphics cards in some of this year's most anticipated games. These videos can be viewed on the AMD website.






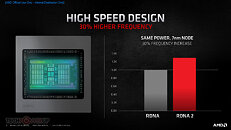
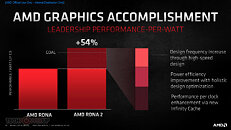
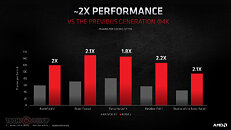



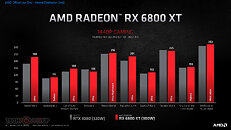



















AMD Radeon RX 6000 Series graphics cards are built upon groundbreaking AMD RDNA 2 gaming architecture, a new foundation for next-generation consoles, PCs, laptops and mobile devices, designed to deliver the optimal combination of performance and power efficiency. AMD RDNA 2 gaming architecture provides up to 2X higher performance in select titles with the AMD Radeon RX 6900 XT graphics card compared to the AMD Radeon RX 5700 XT graphics card built on AMD RDNA architecture, and up to 54 percent more performance-per-watt when comparing the AMD Radeon RX 6800 XT graphics card to the AMD Radeon RX 5700 XT graphics card using the same 7 nm process technology.


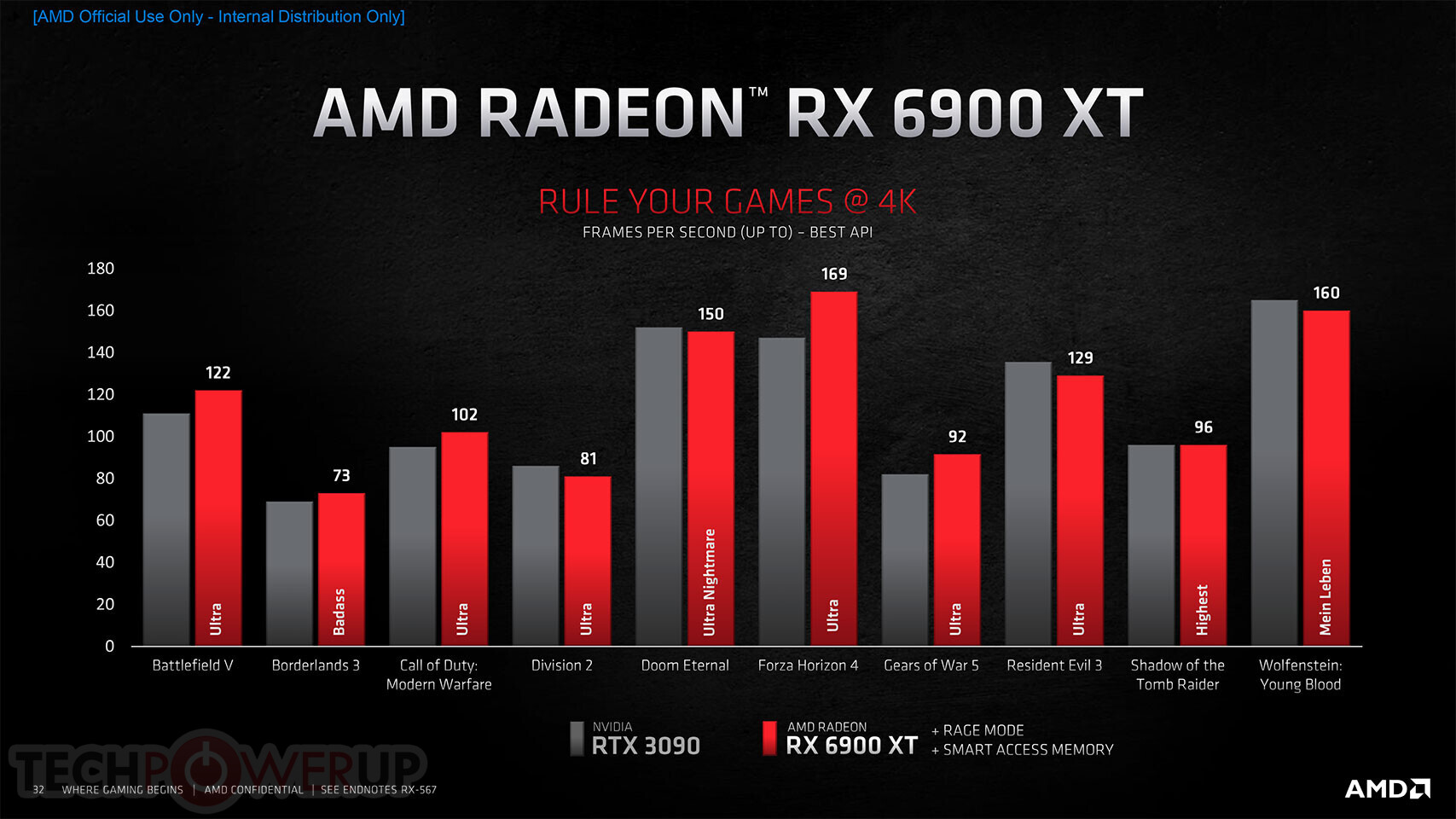
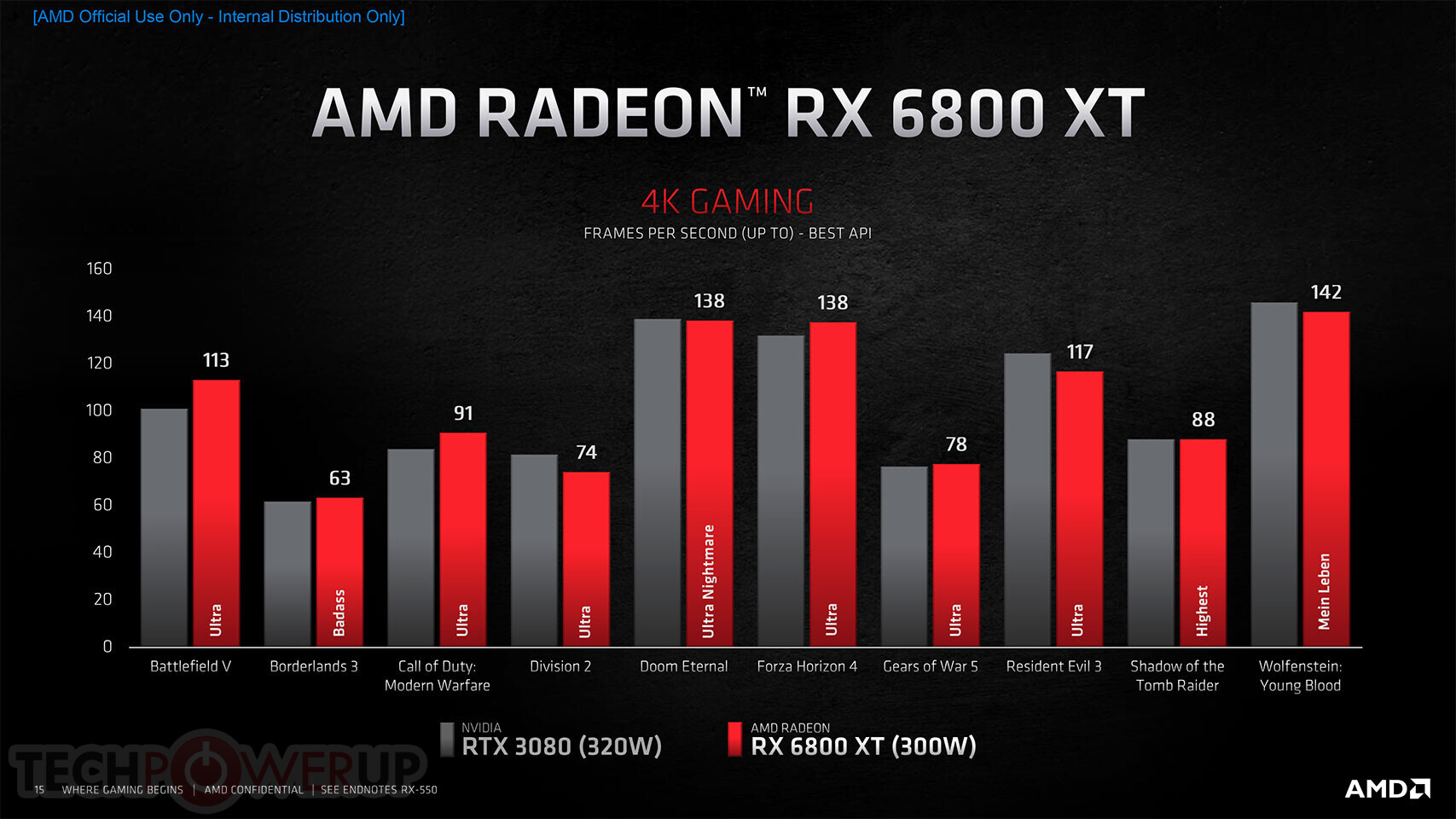
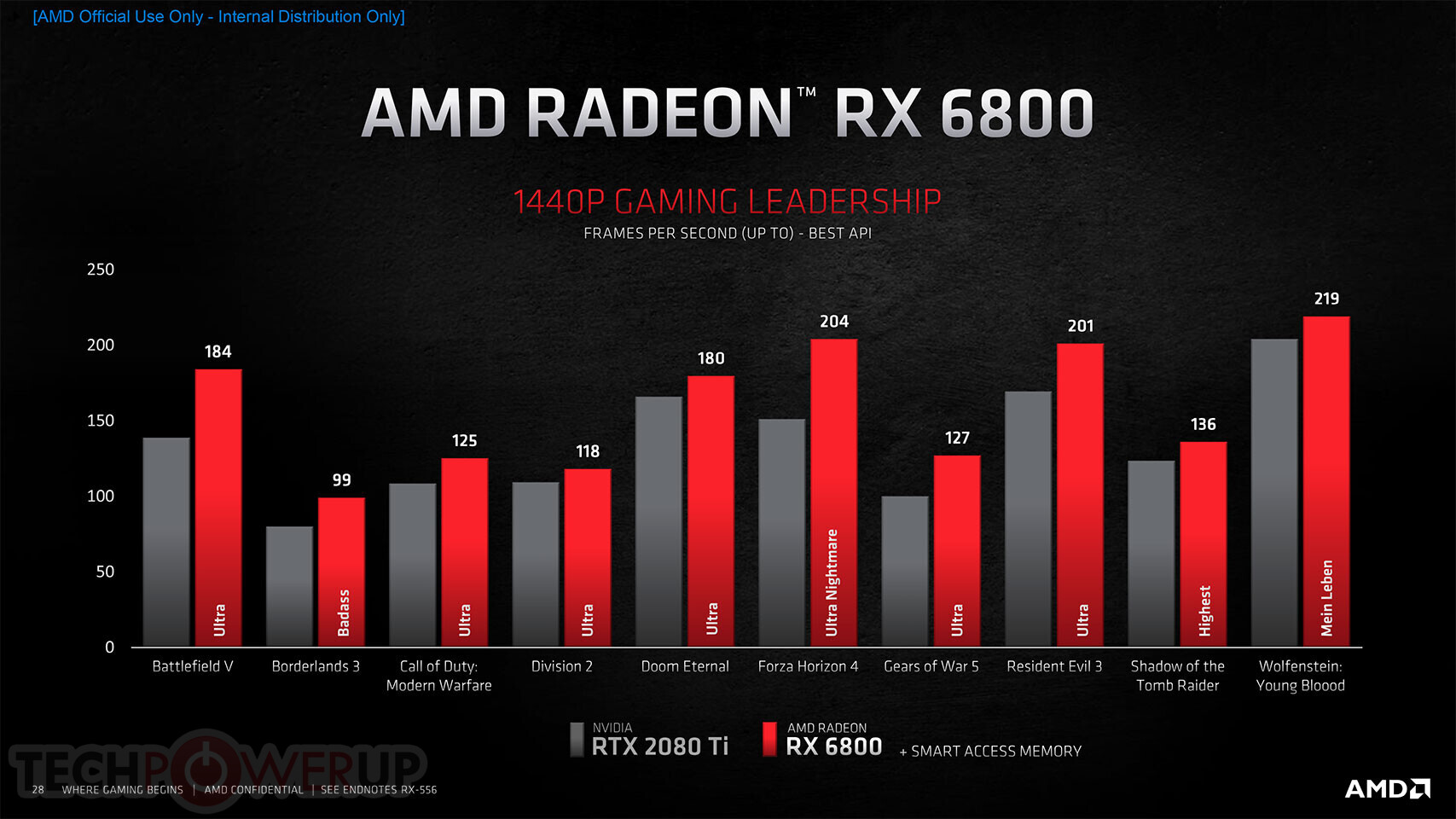
"Today's announcement is the culmination of years of R&D focused on bringing the best of AMD Radeon graphics to the enthusiast and ultra-enthusiast gaming markets, and represents a major evolution in PC gaming," said Scott Herkelman, corporate vice president and general manager, Graphics Business Unit at AMD. "The new AMD Radeon RX 6800, RX 6800 XT and RX 6900 XT graphics cards deliver world class 4K and 1440p performance in major AAA titles, new levels of immersion with breathtaking life-like visuals, and must-have features that provide the ultimate gaming experiences. I can't wait for gamers to get these incredible new graphics cards in their hands."
Powerhouse Performance, Vivid Visuals & Incredible Gaming Experiences
AMD Radeon RX 6000 Series graphics cards support high-bandwidth PCIe 4.0 technology and feature 16 GB of GDDR6 memory to power the most demanding 4K workloads today and in the future. Key features and capabilities include:
Powerhouse Performance
- AMD Infinity Cache - A high-performance, last-level data cache suitable for 4K and 1440p gaming with the highest level of detail enabled. 128 MB of on-die cache dramatically reduces latency and power consumption, delivering higher overall gaming performance than traditional architectural designs.
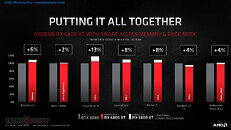
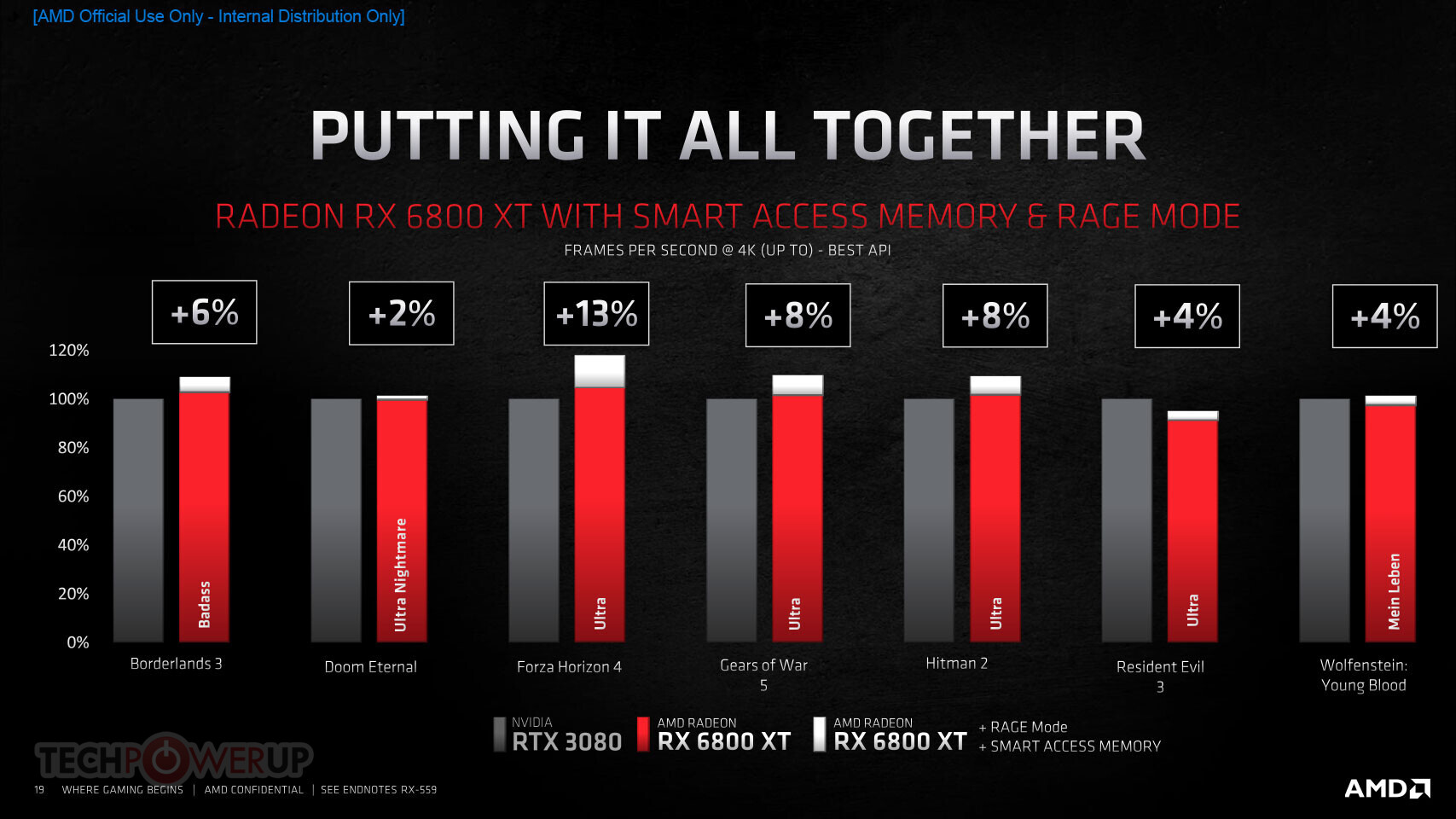
- AMD Smart Access Memory - An exclusive feature of systems with AMD Ryzen 5000 Series processors, AMD B550 and X570 motherboards and Radeon RX 6000 Series graphics cards. It gives AMD Ryzen processors greater access to the high-speed GDDR6 graphics memory, accelerating CPU processing and providing up to a 13-percent performance increase on a AMD Radeon RX 6800 XT graphics card in Forza Horizon 4 at 4K when combined with the new Rage Mode one-click overclocking setting.9,10
- Built for Standard Chassis - With a length of 267 mm and 2x8 standard 8-pin power connectors, and designed to operate with existing enthusiast-class 650 W-750 W power supplies, gamers can easily upgrade their existing large to small form factor PCs without additional cost.
- DirectX 12 Ultimate Support - Provides a powerful blend of raytracing, compute, and rasterized effects, such as DirectX Raytracing (DXR) and Variable Rate Shading, to elevate games to a new level of realism.
- DirectX Raytracing (DXR) - Adding a high performance, fixed-function Ray Accelerator engine to each compute unit, AMD RDNA 2-based graphics cards are optimized to deliver real-time lighting, shadow and reflection realism with DXR. When paired with AMD FidelityFX, which enables hybrid rendering, developers can combine rasterized and ray-traced effects to ensure an optimal combination of image quality and performance.
- AMD FidelityFX - An open-source toolkit for game developers available on AMD GPUOpen. It features a collection of lighting, shadow and reflection effects that make it easier for developers to add high-quality post-process effects that make games look beautiful while offering the optimal balance of visual fidelity and performance.
- Variable Rate Shading (VRS) - Dynamically reduces the shading rate for different areas of a frame that do not require a high level of visual detail, delivering higher levels of overall performance with little to no perceptible change in image quality.
- Microsoft DirectStorage Support - Future support for the DirectStorage API enables lightning-fast load times and high-quality textures by eliminating storage API-related bottlenecks and limiting CPU involvement.
- Radeon Software Performance Tuning Presets - Simple one-click presets in Radeon Software help gamers easily extract the most from their graphics card. The presets include the new Rage Mode stable over clocking setting that takes advantage of extra available headroom to deliver higher gaming performance.
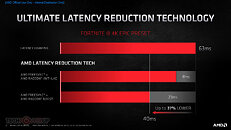
- Radeon Anti-Lag - Significantly decreases input-to-display response times and offers a competitive edge in gameplay.
In the coming weeks, AMD will release a series of videos from its ISV partners showcasing the incredible gaming experiences enabled by AMD Radeon RX 6000 Series graphics cards in some of this year's most anticipated games. These videos can be viewed on the AMD website.
- DIRT 5 - October 29
- Godfall - November 2
- World of Warcraft : Shadowlands - November 10
- RiftBreaker - November 12
- FarCry 6 - November 17
- AMD Radeon RX 6800 and Radeon RX 6800 XT graphics cards are expected to be available from global etailers/retailers and on AMD.com beginning November 18, 2020, for $579 USD SEP and $649 USD SEP, respectively. The AMD Radeon RX 6900 XT is expected to be available December 8, 2020, for $999 USD SEP.
- AMD Radeon RX 6800 and RX 6800 XT graphics cards are also expected to be available from AMD board partners, including ASRock, ASUS, Gigabyte, MSI, PowerColor, SAPPHIRE and XFX, beginning in November 2020.































394 Comments on AMD Announces the Radeon RX 6000 Series: Performance that Restores Competitiveness
But using that as an argument that AMD will try to quicken their GPU development pace? Nah, sorry, not buying that. 16 months between RDNA 1 and RDNA 2. Now we're supposed to get RDNA 3 in < 14 months? And remember, a launch later in the year than this isn't happening no matter what. It's either pre holiday season or CES. Which makes that 12 months, not 14. I really don't see that as likely. I'll be more than happy to be proven wrong, but I'm definitely sticking to a more cautious approach here.
DDR5 is a given, PCIe 5.0 is not much of a necessity even on servers. Of course with Xilinx (acquisition) they might surprise us or something.
CUs were in Vega, and are a decent unit to think about while programming the GPU. WGPs work really hard to "pretend" to work like 2x CUs for backwards compatibility purposes... but they're really just one unit now.
-----
As such: the proper term for those 40x clusters on your RDNA2 die shot is Workgroup Processor (WGP)... or "Dual-compute units" (if you want to make a comparison to Vega).
www.computerbase.de/2020-10/radeon-rx-6800-6800-xt-6900-xt-benchmarks/
www.amd.com/en/gaming/graphics-gaming-benchmarks
Results chop and change a bit, but it gives an idea what to expect.
It’s not really that RDNA2 architecture/IC doesn’t scale well on different resolutions. Or that it does better at lower ones. It’s the Ampere architecture that doesn’t scale well across resolutions.
And you can see that from benchmarks comparing Turing vs Ampere. Turing and RDNA2 have a more “normal” scaling across the 3 well known 1080p, 1440p and 4K.
Seeing benchmarks of Turing vs Ampere across the 3 res you can identify that as you going up Ampere is getting away from Turing to reach the avg relative perf gains of around 30% on 4K. But on 1080p that difference is “only” 20%.
It’s a matter of Ampere’s architecture.
Also, this relative comparison (we don’t actually have full benches between Turing and RDNA2) short of confirms that AMD’s IC with the high (effective) bandwidth is working well and delivers its promises as a real wide bus.
For my simple non-technical (let alone professional) understanding and explanation, I’m thinking that if IC is truly delivering wide bandwidth (800+bit effective) across different workload levels (up to 4K that is more common than 8K) and scale well across them then the real bottleneck for any better performance is, as you also stated indirectly or not, the cores of the GPU and its surrounding I/O. And if really true they’ve manage to remove bandwidth bottleneck completely, up to 4K at least.
It’s radical! But also not a discovery of the wheel. I can’t think that nVidia’s engineers haven’t think of such implementation. But I can compare nVidia’s approach to the one of Intel. AMD has done steps to CPU world for a unified arch with chiplets that scale really well from just 1 to a large number of them. With its cons.
Intel does not do that but rather was always betting on a more strong arch in its core but couldn’t scale well beyond a number. Today’s nVidia’s approach is doing the same on reverse. It performs better on heavy workloads but does not scale well on lighter ones.
nVidia can’t implement such large cache because doesn’t have room for it in its arch, occupied by Tensor and RT cores. That’s why they need the super high speed 6X VRAM to keep up feeding the cuda cores with data.
In a far edged sense, you can say that AMDs arch (both CPU/GPU) is more of opened sourced and nVidia’s more closed and proprietary. Also RDNA in general is a more of a gaming approach and Ampere(starting with Turing) is more of a work load one that can do well in other loads than gaming, like CGN that was really strong outside gaming.
Rumors say that the next RDNA3 will be more close to ZEN2/3 approach. Chunks of cores/dies tied together with large pools of cache.
That’s why I believe it will not come soon. It will be way more than a year.
The reality is only a small subset of data is all that necessary to keeping the GPU fed to not stall. The majority of the data (in a gaming context anyway) isn't anywhere near as latency sensitive and can be much more flexible for when it comes across the bus. IC helps by doing two things. It
A: Stops writes and subsequent retrievals from going back out to general memory for the majority of that data (letting it exist in cache, where its likely a shader is going to retrieve that information from again), and
B: It helps act as a buffer for further deprioritising data retrieval, letting likely needed data be retrieved earlier, momentarily held in cache, then ingested to the shader pipeline than written back out to VRAM.
As for Nvidia, yep, they would have, but the amount of die space being chewed for even 128mb of cache is pretty ludicrously large. AMD has balls chasing such a strategy tbh (but is probably why we saw 384 bit Engineering Sample cards earlier in the year, if IC didn't perform, they could fall back to a wider bus).
Prior to this, AMD struggled with instruction pipeline functions. Successively, they streamlined the pipeline operation flow, dropped instruction latency to 1 and started implementing dual issued operations. That, or I don't know how they can increase shader speed by 7.9x folds implementing simple progressions to the same architecture.And remember, this is only because they had previously experimented with it, otherwise there would be no chance that they know first hand how much power budget it would cost them. Sram has a narrow efficiency window.
There used to be a past notice which compared AMD and Intel's cell to transistor ratios, with the summary being AMD had integrated higher and more efficient transistor count units. All because of available die space.
If PCIE 4.0 doubled the bandwidth and cut the I/O bottleneck in half and this infinity cache is doing similarly that's a big deal for Crossfire. Mantle/Vulkan,DX12, VRS, Direct Storage API, Infinity Fabric, Infinity Cache, PCIE 4.0 and other things all make mGPU easier if anything the only real barrier developers.
I feel like AMD should just do a quincunx socket setup. Sounds a bit crazy, but they could have 4 APU's and a central processor. Infinity fabric and infinity cache between the 4-APU's and the central processor. A shared quad channel memory for the central processor with shared dual channel access to it from the surrounding APU's. The APU's would have 2 cores each to communicate with the adjacent APU's and the rest could be GPU design. The central processor would probably be a pure CPU design high IPC high frequency perhaps a bigLITTLE design a beastly single core central design the heart of the unit and 8-smaller surrounding physical cores handling odd and ends. There could be a lot of on the fly compression/decompression involved as well to maximize bandwidth and increase I/O. The chipset would be gone entirely and just integrated into the CPU design through the socketed chips involved. Lots of bandwidth, processing, single core performance along with multi-core performance and load balancing and head distribution and quick and efficient data transfer between different parts. It's a fortress of sorts, but it could probably fit within a ATX design reasonably well. You might start out with dual channel/quad channel with two socketed chips the socketed heart/brain and along with a APU and build it up down the road for scalable performance improvements. They could integrate FPGA tech into the equation, but that's another matter and cyborg matter we probably shouldn't speak of right now though the cyborg is coming.If I'm not mistaken RNDA transitioned to some form of twin CU design task scheduling work groups that allows for kind of a serial and/or parallel performance flexibility within them. I could be wrong on my interpretation of them, but I think it allows them double down for a single task or split up and each handle two smaller tasks within the same twin CU grouping. Basically a working smarter not harder hardware design technique. Granular is where it is at more neurons. I think ideally you want a brute force single core that occupies the most die space and scale downward by like 50% with twice the core count. So like 4chips 1c/2c/4c/8c chips the performance per core would scale downward as core count increases, but the efficiency per core would increase and provided it can perform the task quickly enough that's a thing it saves power even if it doesn't perform the task as fast though it doesn't always need to either. The 4c/8c chips wouldn't be real ideal for gaming frame rates or anything overall, but they would probably be good for handling and calculating different AI within a game as opposed to pure rendering the AI animations and such don't have to be as quick and efficient as scene rendering for example in general it's just not as vital. I wonder if the variable rate shading will help make better use of core assignments across more cores in theory it should if they are assignable.