Sunday, April 23rd 2023

"Adamantine" L4 Cache Confirmed on Intel "Meteor Lake," Acts as a Passive Interposer
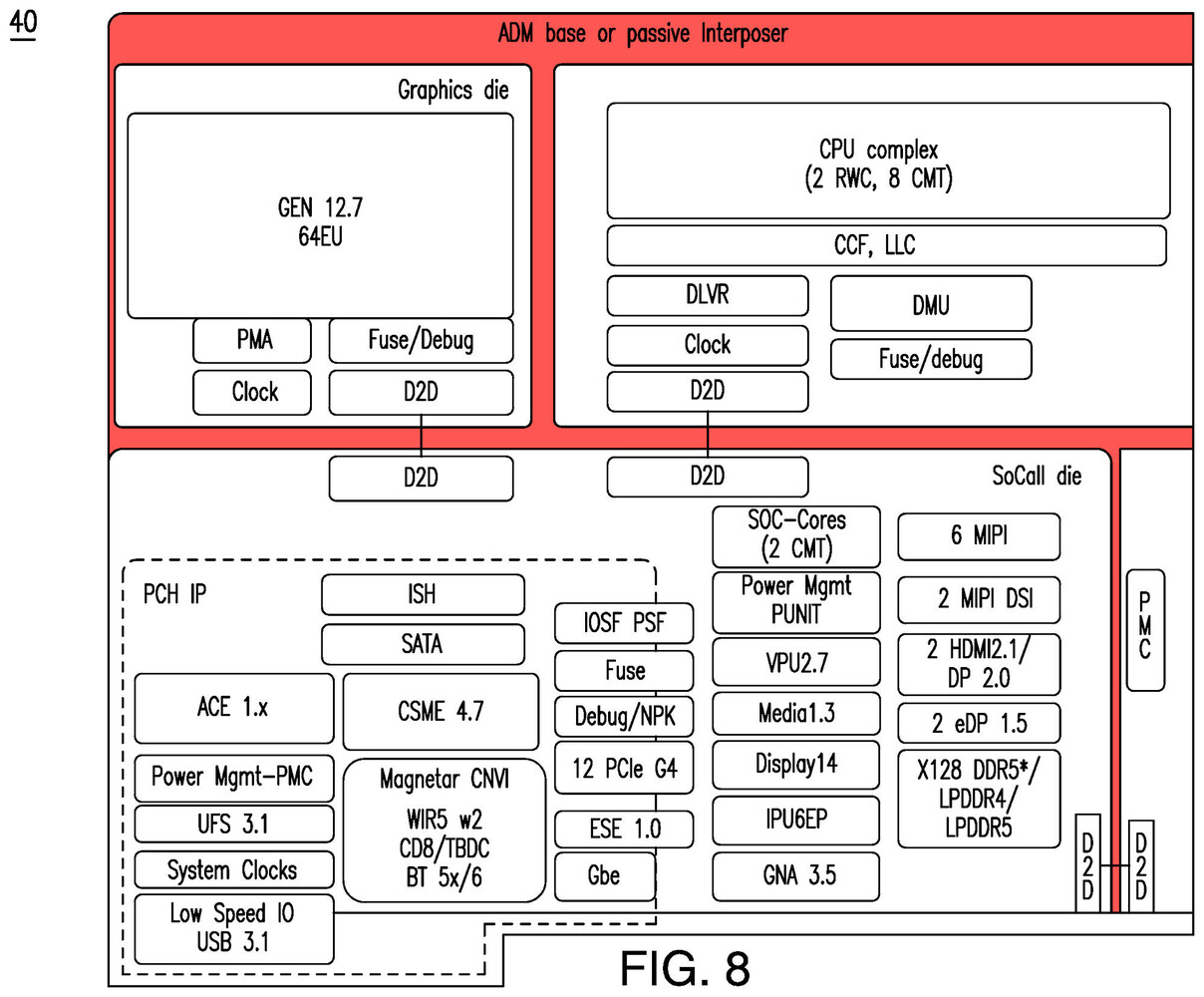
We've known from a recent report that "Meteor Lake" introduces an L4 cache, and now we are learning that it is codenamed "Adamantine," and serves functions resembling that of a passive interposer. Intel's upcoming "Meteor Lake" microarchitecture will power the company's first disaggregated processor for the client segment.
A disaggregated processor is different from an MCM (such as "Clarkdale"), since finer components that make up the processor that otherwise can't exist on their own packages without extreme latency, are made to share a single package via a high-speed interconnect. This disaggregation is purely for economic reasons, so the company needn't use the latest (and most expensive) foundry node for the entire processor, but ration it to the specific components that benefit the most from it. Unlike AMD client processors that disaggregate the CPU cores and the remaining processor I/O into two kinds of chiplets, Intel "Meteor Lake" will see the breaking up of not just CPU cores (compute tile), but also the iGPU on its own tile, besides the platform I/O on separate tiles still. Until now, it was believed that Intel's Foveros packaging innovation, which removes the need for an expensive silicon interposer, would facilitate communications among the various tiles, but now we're learning that the processor will in fact feature an L4 cache memory that provides passive interposer capabilities. By itself, a silicon interposer has no logic. It's only function is to serve as a base for the various logic and memory tiles to be seated on top, so it could provide high-density microscopic wiring among them, which would otherwise not be possible through fiberglass package substrate. An L4 cache is something else, and "Meteor Lake" features an L4 cache acting as a base-tile, and acting like a passive interposer (a misnomer if you understand how it works). This tile has been codenamed "Adamantine."
Until now, it was believed that Intel's Foveros packaging innovation, which removes the need for an expensive silicon interposer, would facilitate communications among the various tiles, but now we're learning that the processor will in fact feature an L4 cache memory that provides passive interposer capabilities. By itself, a silicon interposer has no logic. It's only function is to serve as a base for the various logic and memory tiles to be seated on top, so it could provide high-density microscopic wiring among them, which would otherwise not be possible through fiberglass package substrate. An L4 cache is something else, and "Meteor Lake" features an L4 cache acting as a base-tile, and acting like a passive interposer (a misnomer if you understand how it works). This tile has been codenamed "Adamantine."
"Adamantine" is a base tile with a level-4 (L4) cache memory. The physical media is unknown (whether it is expensive SRAM or eDRAM), and the size would vary among the variants of "Meteor Lake," but what this essentially does is interconnect the various tiles via cache memory. While an "active" interposer is a dumb piece of silicon with high-density wiring as we explained earlier, a "passive" interposer is a memory with connections to the various tiles.
For a tile to communicate with another, data with the right tags is retired to this L4 cache, which is then picked up by its addressee tile. This is essentially the same way the shared L3 caches on Intel processors work, and which is how the CPU cores, iGPU, and uncore components talk to each other. Scale up this concept at a disaggregated processor level, and you understand how the L4 cache works. The individual tiles have their own "last level caches" (LLCs) at their local level. The Compute Tile, for example, has an L3 cache shared among the P-cores and E-core clusters. This is the L3 cache that's exposed to the OS.
To be clear, "Meteor Lake" still has direct die-to-die data connections among the various tiles, but these connections do not follow a radial topology (where each tile is directly connected to every other tile). It's only the SoC tile that appears to have die-to-die connections with the Compute Tile (CPU cores), Graphics Tile (iGPU), I/O tile, and PMC. In scenarios where, for example, the Compute Tile would want to communicate with the Graphics Tile, the L4 cache would serve as a lower latency path, than through the SoC tile.
The size of the L4 cache is really not known, but if it is based on a slower physical media than the SRAM that makes up the L3 cache in the Compute Tile, it stands to reason that it will be considerably larger in size. "Moore's Law is Dead" reports that L4 cache sizes in the range of 128 MB to 512 MB are being tested, although they could even run into gigabytes, the tech channel notes.
Sources:
USPTO, VideoCardz, Moore's Law is Dead (YouTube)
A disaggregated processor is different from an MCM (such as "Clarkdale"), since finer components that make up the processor that otherwise can't exist on their own packages without extreme latency, are made to share a single package via a high-speed interconnect. This disaggregation is purely for economic reasons, so the company needn't use the latest (and most expensive) foundry node for the entire processor, but ration it to the specific components that benefit the most from it. Unlike AMD client processors that disaggregate the CPU cores and the remaining processor I/O into two kinds of chiplets, Intel "Meteor Lake" will see the breaking up of not just CPU cores (compute tile), but also the iGPU on its own tile, besides the platform I/O on separate tiles still.
"Adamantine" is a base tile with a level-4 (L4) cache memory. The physical media is unknown (whether it is expensive SRAM or eDRAM), and the size would vary among the variants of "Meteor Lake," but what this essentially does is interconnect the various tiles via cache memory. While an "active" interposer is a dumb piece of silicon with high-density wiring as we explained earlier, a "passive" interposer is a memory with connections to the various tiles.
For a tile to communicate with another, data with the right tags is retired to this L4 cache, which is then picked up by its addressee tile. This is essentially the same way the shared L3 caches on Intel processors work, and which is how the CPU cores, iGPU, and uncore components talk to each other. Scale up this concept at a disaggregated processor level, and you understand how the L4 cache works. The individual tiles have their own "last level caches" (LLCs) at their local level. The Compute Tile, for example, has an L3 cache shared among the P-cores and E-core clusters. This is the L3 cache that's exposed to the OS.
To be clear, "Meteor Lake" still has direct die-to-die data connections among the various tiles, but these connections do not follow a radial topology (where each tile is directly connected to every other tile). It's only the SoC tile that appears to have die-to-die connections with the Compute Tile (CPU cores), Graphics Tile (iGPU), I/O tile, and PMC. In scenarios where, for example, the Compute Tile would want to communicate with the Graphics Tile, the L4 cache would serve as a lower latency path, than through the SoC tile.
The size of the L4 cache is really not known, but if it is based on a slower physical media than the SRAM that makes up the L3 cache in the Compute Tile, it stands to reason that it will be considerably larger in size. "Moore's Law is Dead" reports that L4 cache sizes in the range of 128 MB to 512 MB are being tested, although they could even run into gigabytes, the tech channel notes.
19 Comments on "Adamantine" L4 Cache Confirmed on Intel "Meteor Lake," Acts as a Passive Interposer
The 5775C was vindicated many years down the road, as it has aged the best out of all quad-core processors up to the 7th gen, but I'm not sure that's a long-term win (at the cost of a short and medium term loss) that Intel intends to repeat. This is a great read, one of the best revisit articles ever written IMO:
www.anandtech.com/show/16195/a-broadwell-retrospective-review-in-2020-is-edram-still-worth-it
In any case, Grandpa Broadwell is surely proud.
However, a cache die could also serve as an interposer if it had a labyrinth of wires connecting the chiplettes and the substrate, and this structure would be separate from the transistors and wires that make up the cache.
Are companies actually granted patents for such obvious "inventions"?
Still, AMD has proven the benefits of large blobs of cache closer to compute, so I'm quietly excited (even if I'll be skipping Meteor Lake due to the 6P limitation regardless).
This seems wrong.
Cache is not a passive component.
An interposer can be passive or active, and if it is active, it usually has just signal re-drivers built in. The extra cache is even more complex and calling it passive is just dumb. A passive interposer is just wiring. Anything else and it’s active.
In the patent it reads ADM or passive interposer. It’s not both.
Anyway, sounds like an interesting new approach to increase preformance with a new level of big cache size. We saturated core count, now make them talk better with each other.
Cache is where AMD hase the upper hand over Intel, and in part what enable them to get same or more pref with much lower wattage.
Intel is bonding active dies together as of Lakefield (2019) and Ponte Vecchio has a variety of dies bonded together, active and passive, cache-and-wireing only. I don't see anything new being done with Meteor lake in this way of connecting.The MTL benefits from tile splitting, and the cost of the base tile using 22FFLs pays for itself well. By the way, the size of Meteor lake is not large enough to use EMIB so that it use Foveros, which means that there is enough wiring in the base tile alone to create a vast free area. In other words, Intel gets new cache at zero cost.
If the 22FFL standard is followed, 128MB can be secured when SRAM is laid out in all the base tiles of the MTL. Excluding wiring, etc., it would be about 48-64MB. If you can use eDRAM for the base tiles, you can triple that to 144-192MB. This is about what can be secured at zero cost.
Couple that with delaying the launch to within weeks from Skylake with mainstream socket DDR4, incompatibility with the Z87 chipset and exceptionally high prices at the time, Broadwell-C was largely a commercial failure.
I picked one up for cheap a few years down the road, it was great, but my Z97 board malfunctioned and the prices they command nowadays aren't worth it. I flipped it and it went fast, too.
Wasn't the infamous 4770 a contemporary of the 5775c? The 4770 had an infamous rep. as a great overclocker.