Thursday, December 19th 2024

Microsoft Acquired Nearly 500,000 NVIDIA "Hopper" GPUs This Year
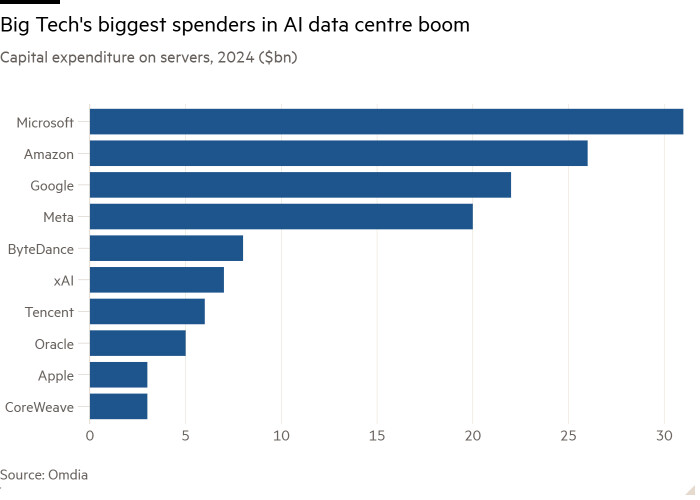
Microsoft is heavily investing in enabling its company and cloud infrastructure to support the massive AI expansion. The Redmond giant has acquired nearly half a million of the NVIDIA "Hopper" family of GPUs to support this effort. According to market research company Omdia, Microsoft was the biggest hyperscaler, with data center CapEx and GPU expenditure reaching a record high. The company acquired precisely 485,000 NVIDIA "Hopper" GPUs, including H100, H200, and H20, resulting in more than $30 billion spent on servers alone. To put things into perspective, this is about double that of the next-biggest GPU purchaser, Chinese ByteDance, who acquired about 230,000 sanction-abiding H800 GPUs and regular H100s sources from third parties.
Regarding US-based companies, the only ones that have come close to the GPU acquisition rate are Meta, Tesla/xAI, Amazon, and Google. They have acquired around 200,000 GPUs on average while significantly boosting their in-house chip design efforts. "NVIDIA GPUs claimed a tremendously high share of the server capex," Vlad Galabov, director of cloud and data center research at Omdia, noted, adding, "We're close to the peak." Hyperscalers like Amazon, Google, and Meta have been working on their custom solutions for AI training and inference. For example, Google has its TPU, Amazon has its Trainium and Inferentia chips, and Meta has its MTIA. Hyperscalers are eager to develop their in-house solutions, but NVIDIA's grip on the software stack paired with timely product updates seems hard to break. The latest "Blackwell" chips are projected to get even bigger orders, so only the sky (and the local power plant) is the limit.


Source:
Financial Times (Report and Charts)
Regarding US-based companies, the only ones that have come close to the GPU acquisition rate are Meta, Tesla/xAI, Amazon, and Google. They have acquired around 200,000 GPUs on average while significantly boosting their in-house chip design efforts. "NVIDIA GPUs claimed a tremendously high share of the server capex," Vlad Galabov, director of cloud and data center research at Omdia, noted, adding, "We're close to the peak." Hyperscalers like Amazon, Google, and Meta have been working on their custom solutions for AI training and inference. For example, Google has its TPU, Amazon has its Trainium and Inferentia chips, and Meta has its MTIA. Hyperscalers are eager to develop their in-house solutions, but NVIDIA's grip on the software stack paired with timely product updates seems hard to break. The latest "Blackwell" chips are projected to get even bigger orders, so only the sky (and the local power plant) is the limit.


27 Comments on Microsoft Acquired Nearly 500,000 NVIDIA "Hopper" GPUs This Year
MS would be stupid not to provide a solution for customer demands.
They were slow initially with bringing GPU acceleration/compute into Azure ~10 years ago, with AWS being much quicker to implement it (admittedly a large part of that probably due to hypervisor being ready to work with different vGPU sharing/partitioning implementations) - I don't think they are gonna be in the same position again.
Some things never change do they :)
I guess with MS/AWS/Google there is the element that they are hosts for others compute needs so not all of that money is going on resources being used by those companies themselves...
But still, it's not a pretty picture, especially when you consider Meta's massive spending which is likely almost entirely internal usage, probably for making more AI slop to push into Facebook... not that Bytedance or xAI are any better even if lower amounts spent...
www.wired.com/story/big-tech-data-centers-cheap-energy/
If so, that does sound mad. Bandwidth will always be an issue here, moving data around is the biggest driver of energy consumption. I would predict MORE local or edge processing, AI or not.
I guess the issue was more about just the passthrough to the rented VM and allocation of such resources per node.There's a lot of that going on, like all the photo tagging and search stuff in Androids and iPhones, as well as stuff like transcription in Whatsapp. Models on the edge are always cool, albeit sometimes lackluster (Whatsapp's transcription model is pretty anemic).
leeches.hopefully ill be dead by that point.
Hope MS dont end up like FB with their Metaverse universe where things were like virtual room simulator with a 2006 Online game
This is gonna sound a bit like a 'The Register' post, but I guess it's worth sharing.
What we see instead is that all these new things are just added on top of what we already have. That is why you own a mobile phone, a PC, and possibly a console too, and also a Smart TV - and you can watch TV on all of them, you can game on all of them, and if you connect a keyboard and have internet you can probably even do your productive tasks on all of them - or most.
Look at security cams. A few years ago, most of what you could get were like Ring - where your security video goes into the cloud and you have no access to it unless you pay a monthly fee. It didn't take too long for this to fall apart, giving rise to alternatives like Eufy, Arlo, and Blink. I know many people who bought Ring early on, and have switched due to a combination of lack of privacy and being nickel-and-dimed.
Though few here are old enough to remember it, same thing was tried with internet access in the 80s and 90s. AOL and Prodigy are later examples of this, where you had a sort of pseudo-access to the internet but mostly only via using the products that they built for you - products which would constantly throw up ads and otherwise were intrusive. But that was never what the consumer wanted, and resulted in thousands of mom-n-pop ISPs shooting up everywhere that simply provided dial-up networking. It was a decade later that the big players begrudgingly gave consumers the simple direct access they wanted.
And going back even further, in the 1970s to early 80s we had time-share. Everyone was supposed to have a dumb terminal with a modem in their home, all compute resources were "in the cloud" aka on the mainframe or other big-iron centralized system you were dialing up. This began to fall apart the moment personal PCs appeared.
I see no reason to think that the current mania will end any differently.
"Willow’s performance on this benchmark is astonishing: It performed a computation in under five minutes that would take one of today’s fastest supercomputers 1025 or 10 septillion years. "
-Hartmut Neven
Founder and Lead, Google Quantum AI
Then Enshittification kicks in...
Corporate profits must continue to rise and if not profits, then revenue growth. At some point, the company has gotten all the consumers it was going to get and then the Squeeze starts. Quality drops, prices go up, and innovation stagnates.