SiFive's New High-Performance Processors Offer a Significant Upgrade for Wearable and Consumer Products
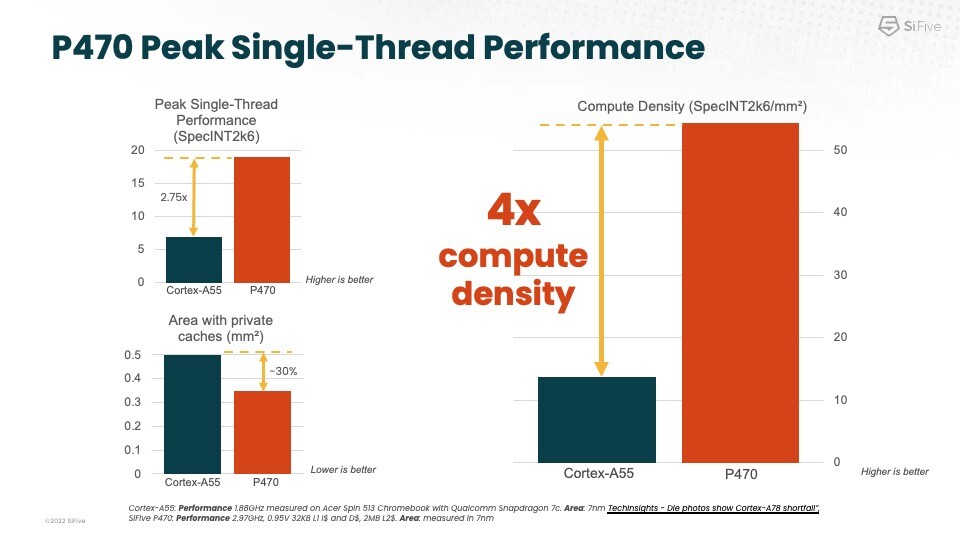
SiFive, Inc. the founder and leader of RISC-V computing, today announced two new products that address the need for high performance and efficiency in a small size in high volume applications like wearables, smart home, industrial automation, AR/VR, and other consumer devices. The SiFive Performance P670 and P470 RISC-V processors bring unparalleled compute performance and efficiency that is significantly raising the bar for innovative designs in these high-volume markets. The modern and innovative SiFive design methodologies bring raw compute density that is a substantial advantage for SiFive Performance products and also translates into significant cost savings for customers.
"The P670 and P470 are specifically designed for, and capable of handling the most demanding workloads for wearables and other advanced consumer applications. These new products offer powerful performance and compute density for companies looking to upgrade from legacy ISAs," said Chris Jones, SiFive VP of Product. "We have optimized these new RISC-V Vector enabled products to deliver the performance and efficiency improvements the industry has long been asking for, and we are in evaluations with a number of top-tier customers. Additionally, as the upstream enablement of RISC-V has started within the Android Open Source Project, (AOSP), designers will have unrivaled choice and flexibility as they consider the positive implications with that platform for future designs."



"The P670 and P470 are specifically designed for, and capable of handling the most demanding workloads for wearables and other advanced consumer applications. These new products offer powerful performance and compute density for companies looking to upgrade from legacy ISAs," said Chris Jones, SiFive VP of Product. "We have optimized these new RISC-V Vector enabled products to deliver the performance and efficiency improvements the industry has long been asking for, and we are in evaluations with a number of top-tier customers. Additionally, as the upstream enablement of RISC-V has started within the Android Open Source Project, (AOSP), designers will have unrivaled choice and flexibility as they consider the positive implications with that platform for future designs."