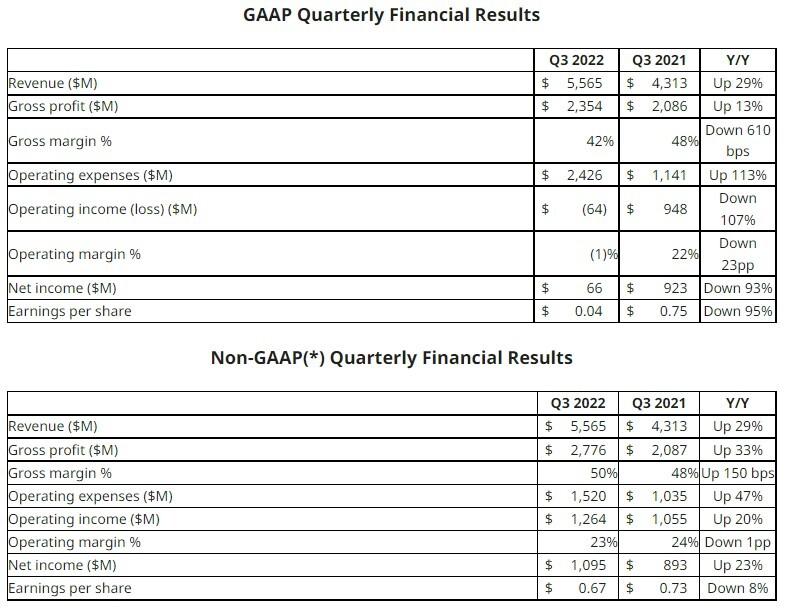
TSMC's 3 nm Node at Near 50 Percent Utilisation, Other Nodes Seeing Lower Demand
Based on multiple reports out of Taiwan, TSMC is seeing increased utilisation of its 3 nm node and its production line is now at close to 50 percent utilisation. The main customer here is without a doubt Apple and TSMC is churning out some 50-55,000 wafers a month on its 3 nm node. TSMC is also getting ready to start production on its N3E node later this year, which will see some customers move to the node.
However, it's not all good news, as TSMC is seeing a decline in utilisation on its 5/4 and 7/6 nm nodes as demand has dropped significantly here, with different news outlets reporting different figures. Some are suggesting the 7/6 nm nodes might have dropped as low as to 50 percent utilisation, others mention 70 percent. The 5/4 nm nodes aren't anywhere nearly as badly affected and remain at around 80 percent utilisation. The good news for TSMC is that this is expected to be a temporary slump in demand and most of its leading edge nodes should be back at somewhere around a 90 percent utilisation rate by the second half of the year. However, this depends on what the demand for its partners' products will look like going forward, as many of TSMC's customers are seeing lower demand for their products in turn.
However, it's not all good news, as TSMC is seeing a decline in utilisation on its 5/4 and 7/6 nm nodes as demand has dropped significantly here, with different news outlets reporting different figures. Some are suggesting the 7/6 nm nodes might have dropped as low as to 50 percent utilisation, others mention 70 percent. The 5/4 nm nodes aren't anywhere nearly as badly affected and remain at around 80 percent utilisation. The good news for TSMC is that this is expected to be a temporary slump in demand and most of its leading edge nodes should be back at somewhere around a 90 percent utilisation rate by the second half of the year. However, this depends on what the demand for its partners' products will look like going forward, as many of TSMC's customers are seeing lower demand for their products in turn.