Tuesday, August 18th 2020

Raja Koduri Previews "PetaFLOPs Scale" 4-Tile Intel Xe HP GPU
Raja Koduri, Intel's chief architect and senior vice president of Intel's discrete graphics division, has today held a talk at HotChips 32, the latest online conference of 2020, that shows off the latest architectural advancements in the semiconductor industry. So Intel has prepared two talks, one about Ice Lake-SP server CPUs and one about Intel's efforts in the upcoming graphics card launch. So what has Intel been working on the whole time? Raja Koduri took over the talk and has benchmarked the upcoming GPU and recorded how much raw power the GPUs posses, possibly counting in PetaFLOPs.
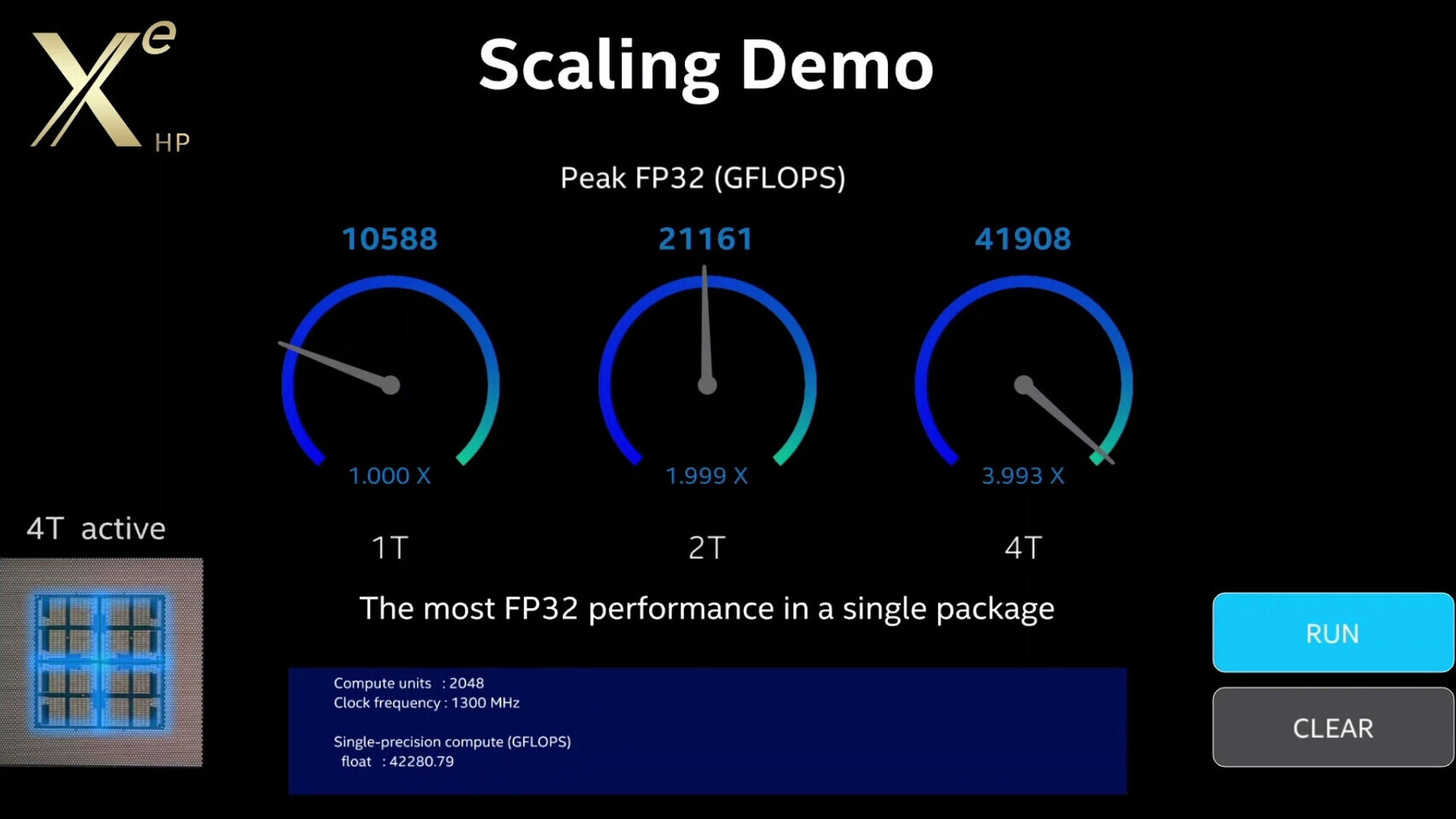
When Mr. Koduri got to talk, he pulled the 4-tile Xe HP GPU out of his pocket and showed for the first time how the chip looks. And it is one big chip. Featuring 4 tiles, the GPU represents Intel's fastest and biggest variant of Xe HP GPUs. The benchmark Intel ran was made to show off scaling on the Xe architecture and how the increase in the number of tiles results in a scalable increase in performance. Running on a single tile, the GPU managed to develop the performance of 10588 GFLOPs or around 10.588 TeraFLOPs. When there are two tiles, the performance scales almost perfectly at 21161 GFLOPS (21.161 TeraFLOPs) for 1.999X improvement. At four tiles the GPU achieves 3.993 times scaling and scores 41908 GFLOPs resulting in 41.908 TeraFLOPS, all measured in single-precision FP32.

 Mr. Koduri has mentioned that the 4-tile chip is capable of "PetaFLOPs performance" which means that the GPU is going to be incredibly fast for tasks like machine learning and AI. Given that the GPU supports tensor cores if we calculate that it has 2048 compute units (EUs), capable of performing 128 operations per cycle (128 TOPs) and the fact that there are about 2 FMA (Fused Multiply-Add) units, that equals to about 524,288 FLOPs of AI power. This means that the GPU needs to be clocked at least at 2 GHz clock to achieve the PetaFLOP performance target, or have more than 128 TOPs of computing ability.
Mr. Koduri has mentioned that the 4-tile chip is capable of "PetaFLOPs performance" which means that the GPU is going to be incredibly fast for tasks like machine learning and AI. Given that the GPU supports tensor cores if we calculate that it has 2048 compute units (EUs), capable of performing 128 operations per cycle (128 TOPs) and the fact that there are about 2 FMA (Fused Multiply-Add) units, that equals to about 524,288 FLOPs of AI power. This means that the GPU needs to be clocked at least at 2 GHz clock to achieve the PetaFLOP performance target, or have more than 128 TOPs of computing ability.
Source:
Tom's Hardware
When Mr. Koduri got to talk, he pulled the 4-tile Xe HP GPU out of his pocket and showed for the first time how the chip looks. And it is one big chip. Featuring 4 tiles, the GPU represents Intel's fastest and biggest variant of Xe HP GPUs. The benchmark Intel ran was made to show off scaling on the Xe architecture and how the increase in the number of tiles results in a scalable increase in performance. Running on a single tile, the GPU managed to develop the performance of 10588 GFLOPs or around 10.588 TeraFLOPs. When there are two tiles, the performance scales almost perfectly at 21161 GFLOPS (21.161 TeraFLOPs) for 1.999X improvement. At four tiles the GPU achieves 3.993 times scaling and scores 41908 GFLOPs resulting in 41.908 TeraFLOPS, all measured in single-precision FP32.


32 Comments on Raja Koduri Previews "PetaFLOPs Scale" 4-Tile Intel Xe HP GPU
"At four tiles the GPU achieves 3.993 times scaling and scores 41908 GFLOPs resulting in 41.908 TeraFLOPS, all measured in single-precision FP32. "
Nvidia ampere does 19.5 on single precision. Intel with 1 tile does 10, 4 tiles does 40, I do find it impressive.
Regardless, Intel does seem to have an MCM solution running, so they're doing something.
this is just funny
It manages about 1km or about 1000m or about 100000cm
In addition, between this and their IGPs I'm not seeing how Xe is going to make waves for gaming. This is certainly not the trimmed down gaming die we'll get... but what dó we get? 16 tiles of IGP? :p
All in all, cool test, but pretty pointless and a great way of telling us nothing.
To complement my post, last i heard, 4 tiles would be around 500 watts, imagine to cool that thing down hehe, I mean cooling down a threadripper is hard enough, TR is around 500 watts. I have no idea what they will do, I think they will release a 2 tiles and 1 tile gpus or a more manufacturing friendly approach, only a 2 tiles gpus and price it lower than competition. We will see, I hope they get it right, we need this but knowing Intel, they always price their things very high x the competition.
We will see if latency in whatever interconnect implementation they use won't be an issue, though I presume Intel engineers thought of that and more already and certainly know better than all of us here.
Over long time period I always had "feeling" AMD (ATi) could do ton better if they actually got their software side together.. Even games when tuned right show that sometimes. Its there, just mostly out of reach. :/
Intel seems to be again a bit late to the party, with same issues their CPU have. Too big, too hot. And probably too expensive.
Looks like old ideas desperately trying to keep themselves relevant, despite ever increasing foundry challenges. Its like they love to repeat 10nm. Intel seems to be adamant that extreme specialization and tweaking is the way forward... but isn't that a dead end, ultimately, and probably pretty soon?
I mean it is low entry level design, so for a first attempt we can say "it has potential".
Sounds about right for this guy.
He is in a lot of pressure I tell you hehe, nothing better to show people who do not like him at Intel that he is doing his job.
I'll rehash what I said when Xe was announced: if Intel doesn't provide a competitive product with their initial launch, they absolutely will with their third or fourth generation.