Thursday, January 28th 2021

Apple Patents Multi-Level Hybrid Memory Subsystem
Apple has today patented a new approach to how it uses memory in the System-on-Chip (SoC) subsystem. With the announcement of the M1 processor, Apple has switched away from the traditional Intel-supplied chips and transitioned into a fully custom SoC design called Apple Silicon. The new designs have to integrate every component like the Arm CPU and a custom GPU. Both of these processors need good memory access, and Apple has figured out a solution to the problem of having both the CPU and the GPU accessing the same pool of memory. The so-called UMA (unified memory access) represents a bottleneck because both processors share the bandwidth and the total memory capacity, which would leave one processor starving in some scenarios.
Apple has patented a design that aims to solve this problem by combining high-bandwidth cache DRAM as well as high-capacity main DRAM. "With two types of DRAM forming the memory system, one of which may be optimized for bandwidth and the other of which may be optimized for capacity, the goals of bandwidth increase and capacity increase may both be realized, in some embodiments," says the patent, " to implement energy efficiency improvements, which may provide a highly energy-efficient memory solution that is also high performance and high bandwidth." The patent got filed way back in 2016 and it means that we could start seeing this technology in the future Apple Silicon designs, following the M1 chip.
Update 21:14 UTC: We have been reached out by Mr. Kerry Creeron, an attorney with the firm of Banner & Witcoff, who provided us with additional insights about the patent. Mr. Creeron has provided us with his personal commentary about it, and you can find Mr. Creeron's quote below.



Source:
Apple Patent
Apple has patented a design that aims to solve this problem by combining high-bandwidth cache DRAM as well as high-capacity main DRAM. "With two types of DRAM forming the memory system, one of which may be optimized for bandwidth and the other of which may be optimized for capacity, the goals of bandwidth increase and capacity increase may both be realized, in some embodiments," says the patent, " to implement energy efficiency improvements, which may provide a highly energy-efficient memory solution that is also high performance and high bandwidth." The patent got filed way back in 2016 and it means that we could start seeing this technology in the future Apple Silicon designs, following the M1 chip.
Update 21:14 UTC: We have been reached out by Mr. Kerry Creeron, an attorney with the firm of Banner & Witcoff, who provided us with additional insights about the patent. Mr. Creeron has provided us with his personal commentary about it, and you can find Mr. Creeron's quote below.

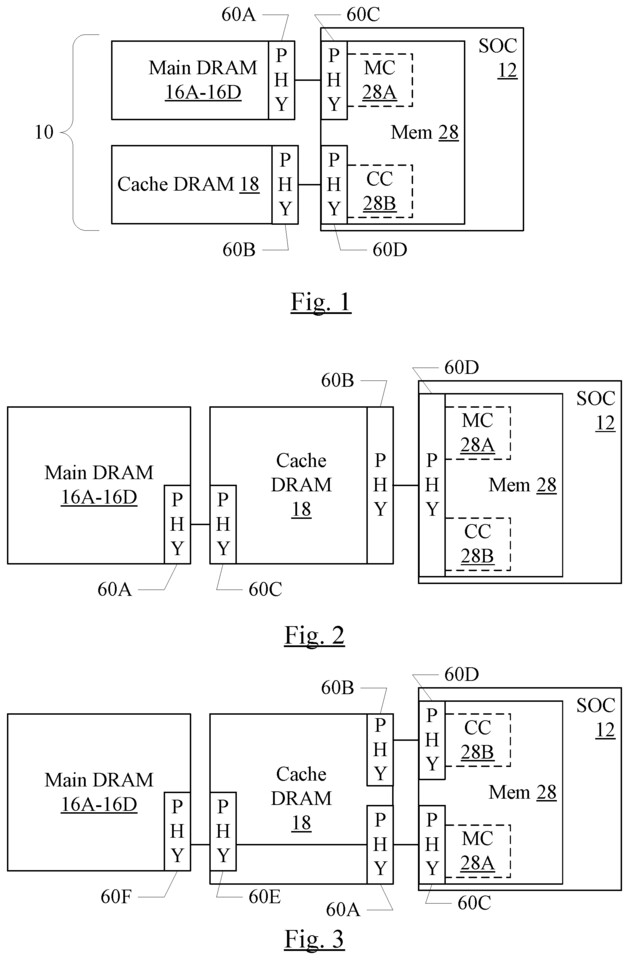

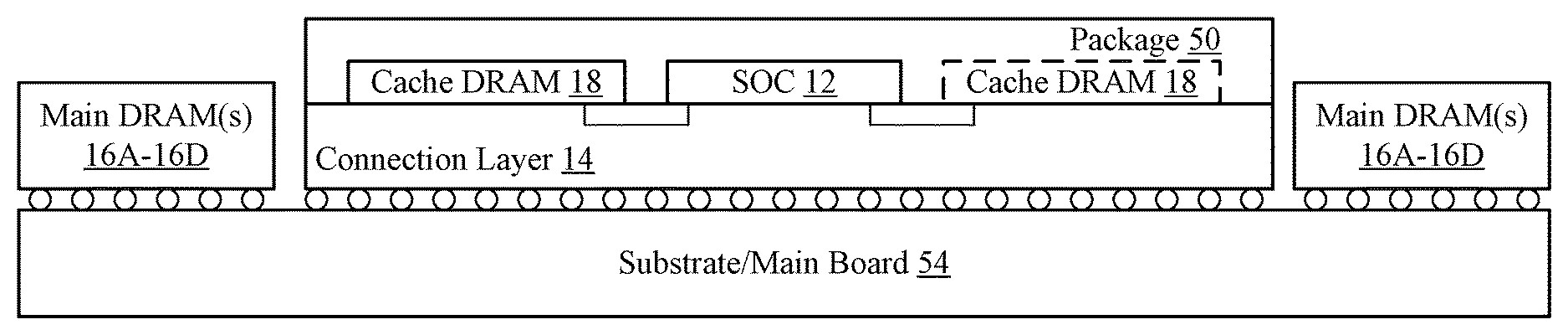
Kerry Creeron—an attorney with the firm of Banner & Witcoff.High-level, the patent covers a memory system having a cache DRAM and that is coupled to a main DRAM. The cache DRAM is less dense and has lower energy consumption than the main DRAM. The cache DRAM may also have higher performance. A variety of different layouts are illustrated for connecting the main and cache DRAM ICs, e.g. in FIGS. 8-13. One interesting layout involves through silicon vias (TSVs) that pass through a stack of main DRAM memory chips.
Theoretically, such layouts might be useful for adding additional slower DRAM to Apple's M1 chip architecture.
Finally, I note that the lead inventor, Biswas, was with PA Semi before Apple Acquired it.
41 Comments on Apple Patents Multi-Level Hybrid Memory Subsystem
So it seems to me like this is just a worse version of what Intel did with their L4 cache.
This is also in the context of Big-Small core setup. So, there may be some in-house special sauce that calls to optimizing that architecture setup against an on-package bit of DRAM.
Throw on some degree of MRAM tech or whatever to provide some quasi speedy permanent cache on the package... Really start veering off that "it's either L$, RAM or on the disk" dogma, and incorporate layers of software priority for OS and applications to help further optimize latency... That could get interesting for reducing the PCB foot print of these devices.
www.servers4less.com/motherboards/system/gigabyte%20tech-ga-586sg?msclkid=64cf237f537e1712d534436eec44604e&utm_source=bing&utm_medium=cpc&utm_campaign=S4L%20Master%20400k&utm_term=4582352152130368&utm_content=Adgroup%20-%20S4L%20Master%20400k
I wonder who they are going to parent troll with this as well.....
With that said though, as the owner of a top of the line MacBook Pro that's expensive as a kidney, I know that Apple will absolutely make you pay through the nose for it.The Apple G3 and G4 had an off die cache on the same package as the CPU. It's nothing new. It just makes sense to have cache closer to the actual cores using it for the sake of latency. It depends on where in the memory hierarchy you need improvement.
Edit: I mean, what does this look like? I used one of these when StarCraft was brand new. This isn't new tech. We just have better tech to use it with.
Edit: Lo and behold, the update says it's just DDR.