Friday, September 29th 2023

AMD Zen 5 Microarchitecture Referenced in Leaked Slides
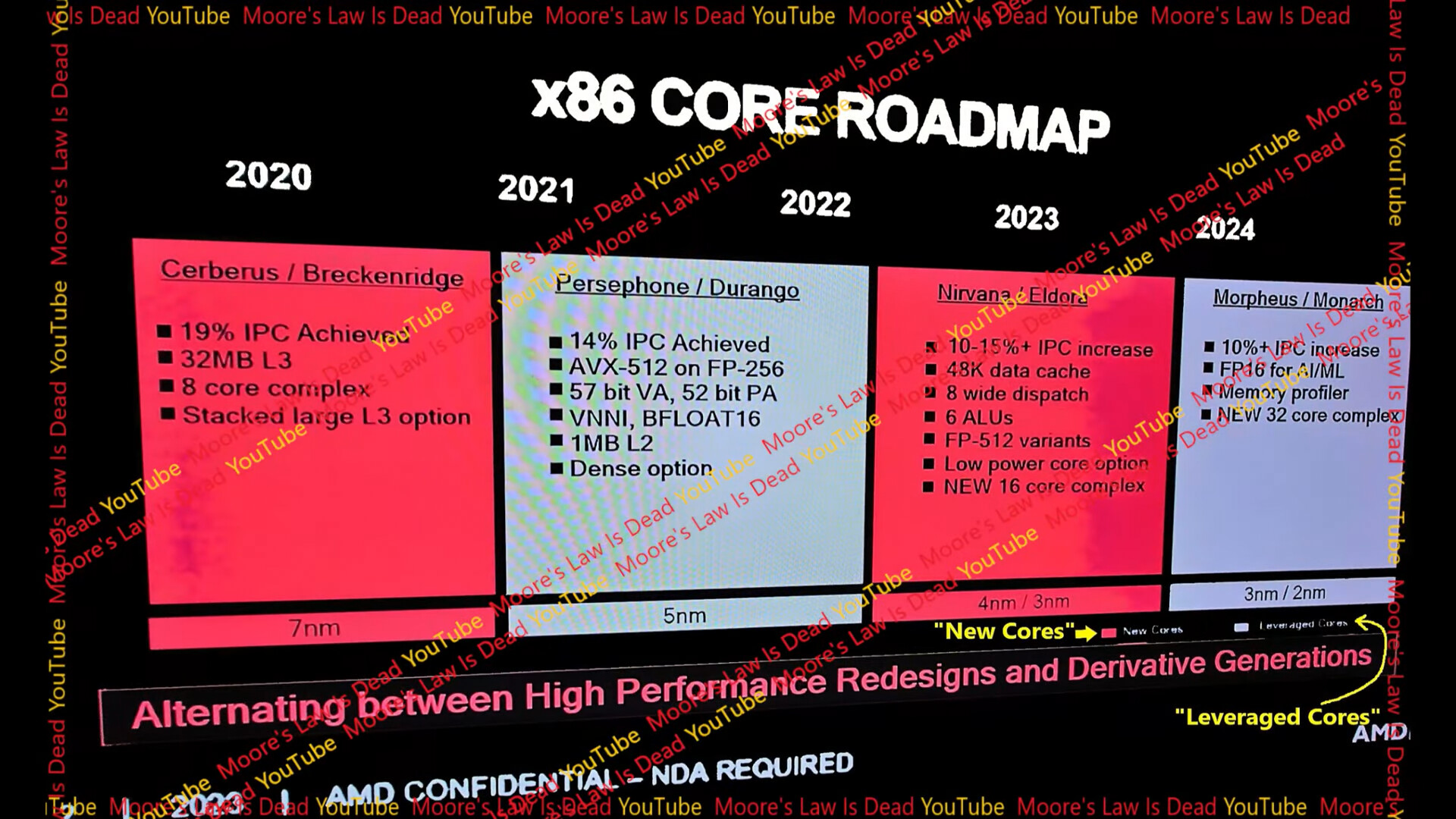
A couple of slides from AMD's internal presentation were leaked to the web by Moore's Law is Dead, referencing what's allegedly the next-generation "Zen 5" microarchitecture. Internally, the performance variant of the "Zen 5" core is referred to as "Nirvana," and the CCD chiplet (CPU core die) based on "Nirvana" cores, is codenamed "Eldora." These CCDs will make up either the company's Ryzen "Granite Ridge" desktop processors, or EPYC "Turin" server processors. The cores themselves could also be part of the company's next-generation mobile processors, as part of heterogenous CCXs (CPU core complex), next to "Zen 5c" low-power cores.
In broad strokes, AMD describes "Zen 5" as introducing a 10% to 15% IPC increase over the current "Zen 4." The core will feature a larger 48 KB L1D cache, compared to the current 32 KB. As for the core itself, it features an 8-wide dispatch from the micro-op queue, compared to the 6-wide dispatch of "Zen 4." The integer execution stage gets 6 ALUs, compared to the current 4. The floating point unit gets FP-512 capabilities. Perhaps the biggest announcement is that AMD has increased the maximum cores per CCX from 8 to 16. At this point we don't know if it means that "Eldora" CCD will have 16 cores, or whether it means that the cloud-specific CCD with 16 "Zen 5c" cores will have 16 cores within a single CCX, rather than spread across two CCXs with smaller L3 caches. AMD is leveraging the TSMC 4 nm EUV node for "Eldora," the mobile processor based on "Zen 5" could be based on the more advanced TSMC 3 nm EUV node.
 The opening slide also provides a fascinating way AMD describes its CPU core architectures. According to this, "Zen 3" and "Zen 5" are new cores, while "Zen 4" and the future "Zen 6" cores are leveraged cores. If you recall, "Zen 3" had provided a massive 19% IPC uplift over "Zen 2," which helped AMD dominate the CPU market. Although with a more conservative 15% IPC gain estimate over "Zen 4," the "Zen 5" core is expected to have as big of an impact on AMD's competitiveness.
The opening slide also provides a fascinating way AMD describes its CPU core architectures. According to this, "Zen 3" and "Zen 5" are new cores, while "Zen 4" and the future "Zen 6" cores are leveraged cores. If you recall, "Zen 3" had provided a massive 19% IPC uplift over "Zen 2," which helped AMD dominate the CPU market. Although with a more conservative 15% IPC gain estimate over "Zen 4," the "Zen 5" core is expected to have as big of an impact on AMD's competitiveness.
Speaking of the "Zen 6" microarchitecture and the "Morpheus" core, AMD is anticipating a 10% IPC increase over "Zen 5," new FP16 capabilities for the core, and a 32-core CCX (maximum core-count). This would see a second round of significant increases in CPU core counts.
Diving deep into the "Zen 5" core, and we see AMD introduce an even more advanced branch prediction unit. If you recall, branch predictor improvements had the largest contribution toward the generational IPC gain of "Zen 4." The new branch predictor comes with zero bubble conditional branches capabilities, accuracy improvements, and a larger BTB (branch target buffer). As we mentioned, the core has a larger 48 KB L1D cache, and an unspecified larger D-TLB. There are throughput improvement across the front-end and load/store stages, with dual basic block fetch units, 8-wide op dispatch/rename; Op Fusion, a 50% increase in ALCs, a deeper execution window, a more capable prefetcher, and updates to the CPU core ISA and security. The dedicated L2 cache per core remains 1 MB in size.
Sources:
cyperalien (Reddit), Moore's Law is Dead (YouTube)
In broad strokes, AMD describes "Zen 5" as introducing a 10% to 15% IPC increase over the current "Zen 4." The core will feature a larger 48 KB L1D cache, compared to the current 32 KB. As for the core itself, it features an 8-wide dispatch from the micro-op queue, compared to the 6-wide dispatch of "Zen 4." The integer execution stage gets 6 ALUs, compared to the current 4. The floating point unit gets FP-512 capabilities. Perhaps the biggest announcement is that AMD has increased the maximum cores per CCX from 8 to 16. At this point we don't know if it means that "Eldora" CCD will have 16 cores, or whether it means that the cloud-specific CCD with 16 "Zen 5c" cores will have 16 cores within a single CCX, rather than spread across two CCXs with smaller L3 caches. AMD is leveraging the TSMC 4 nm EUV node for "Eldora," the mobile processor based on "Zen 5" could be based on the more advanced TSMC 3 nm EUV node.

Speaking of the "Zen 6" microarchitecture and the "Morpheus" core, AMD is anticipating a 10% IPC increase over "Zen 5," new FP16 capabilities for the core, and a 32-core CCX (maximum core-count). This would see a second round of significant increases in CPU core counts.
Diving deep into the "Zen 5" core, and we see AMD introduce an even more advanced branch prediction unit. If you recall, branch predictor improvements had the largest contribution toward the generational IPC gain of "Zen 4." The new branch predictor comes with zero bubble conditional branches capabilities, accuracy improvements, and a larger BTB (branch target buffer). As we mentioned, the core has a larger 48 KB L1D cache, and an unspecified larger D-TLB. There are throughput improvement across the front-end and load/store stages, with dual basic block fetch units, 8-wide op dispatch/rename; Op Fusion, a 50% increase in ALCs, a deeper execution window, a more capable prefetcher, and updates to the CPU core ISA and security. The dedicated L2 cache per core remains 1 MB in size.
111 Comments on AMD Zen 5 Microarchitecture Referenced in Leaked Slides
May I kindly suggest that if you have nothing to give, then give nothing.
MLID "leaks" information, has discussions with insiders and formulates his own conclusions and then releases them to the public as HIS leaks and opinions. You could very easily do the same, if you are not able or willing to do so, then simply do not read or watch what he has to offer, and do not add your empty comments in places like this.Zen 6 is bringing a significant change in packaging, so something along these lines is not just possible, but expected. Intel is also working on something like this, it is codenamed "Adamantine" and was/is aimed to be a 128MB slab of some kind of Cache/RAM, not enough details have been leaked yet to know what this is exactly, but most likely to be L3 or L4 Cache, the question remains as to whether this was a realistic target, how well it works, how much it costs, especially in packaging, what the energy consumption is, will it have drawbacks (energy consumption for example).
That both Intel and AMD are working with advanced packaging techniques, 2.5 and 3D silicon, both active and inactive silicon layers, says a lot about where things are going as the physical, electrical and thermal problems mount as the lithographic processes become more difficult and expensive. The future of CPU's and other performance Silicon is going to end up with fully 3D chips for the performance, with the less performant silicon attached in the traditional manner, off to the side, and perhaps some distance away.
"Chips" have not had such dramatic and exciting changes for a long time, this alone is entertainment for us Geeks.This will change in the not so distant future. AMD is building what some have named as a "Super APU", it has a quad channel memory design - for laptops / notebooks, and one assumes also for desktops.
As it is aimed at laptops, and for gaming, it makes sense to run quad channel RAM with a beefy amount of graphics power. Right now however we can only speculate as to the nature of the RAM, will it be GDDR6/X/7 soldered to the board right next to the APU, or will that be half of the RAM and the rest is DDR5, which would add an extra degree of complexity, or will it all be DDR5, if so will it be soldered down or will the laptops have 4x SODIMM slots.!?!? All unknown ATM, but this is a real planned product and will be using Zen 5 cores, so that gives a timescale.
As for Workstation CPU's, AMD has just announced a new socket for "mini EPYC" CPU's, they have up to 64 Zen 4c cores (standard Zen 4c chiplets, up to 4x16), and reuse the standard I/O die, but have fewer available PCIe lanes, and 6-channel RAM (rather than 12).
There is no reason why AMD could not use this socket for future Workstation CPU's, I would welcome that, and as always, there has been a great deal of speculation about this future potential use of the new SP6 socket.
Video linked below.
AMD "mini-EPYC" Sierra CPU and platform overview.
L3 cache is a spillover cache, and most computational intensive workloads are not L3 cache sensitive, as this is largely a symptom of poorly written software. Adding ever increasing L3 caches isn't an avenue which will unlock new magnitudes of performance, and I don't see the reason to spend precious development resources and die space on getting essentially marginal gains in bad software. What we need is more computational power and throughput.Well, it doesn't quite work that way.
Performance gains from increasing caches depends on the characteristics of the architecture. Also, such gains are usually in the form of diminishing returns, so it requires exponentially more cache to achieve less and less.
We've seen caches change before, sometimes they increase, and sometimes they even decrease, especially when there is a revolutionary new architecture. There are also more things to cache than just size, like number of banks and latency.You know, the few people with sensitive know-how of future products just love pouring out spicy details, risking not only their own career, but also lawsuits and their own livelihood to random nobodys on Youtube, for no apparent gain or purpose. That's why several of these "leakers" claim to have dozens of top sources within AMD, Intel, Nvidia, AiB makers and motherboard makers, because such sources are so abundant and plentiful. It's not like they just find rumors and occasional real stuff on various forums and add some sprinkling to it… ;)
(sarcasm)
In the real world though, these "leakers" are constantly wrong because they are fake.
Architectural details, including cache configuration, threading(SMT…), pipieline design, etc. are set in stone up to several years ahead of an actual product release. The larger the feature, the eariler it has to be decided, as all other design considerations are derived from it. No such details change "last minute". Use this knowledge, and you can dismiss a lot of videos about "leaks".
Also IPC known long before tapeut, they do in fact simulate various design variations, and IPC always comes from architectural features. IPC is instructions per clock, not performance BTW. The only discrepancy here is if they have to disable hardware features, change timings in firmware etc, to account for hardware defects.
So clock speeds will be unknown until late engineering samples arrive, but IPC is known.
It makes perfect sense - you mess with your competitor, send them scrambilng and looking for sources inside their own company that dont exist. Potentially even changing some plans that can be changed like segmentation or price.
This I think will be limited to threadripper et al line ups for the forseeable future until iGPUs become powerful enough to warrant the extra bandwidth needed. It would make sense in certain hand held scenarios and maybe with Samsungs new LPCAMM standard it may become viable but still quite a few years before being market ready.
Intel is basically in the position AMD was back during the Phenom II vs Core2 era - it is cramming a bunch of cores into a cpu and clocking them as high as possible (ignoring much of power consumption considerations) to stay competitive.
In multithreaded workloads, the upper Ryzen 7000 cpus can beat or at least match the top of the line Intel cpus like the i7-13700k and the i9-13900k in productivity while consuming 40%-50%+ less power.
Intel's i-12000 series was slightly ahead of Zen 3/Ryzen 5000 in terms of gaming, but when the Ryzen 7000 series came out, the 7700X with 32mb L3 cache is roughly equal to/slightly slower than Intel i9 cpus and the 7800X3D is a ahead of Intel i9 cpus.
Having just looked it up, LPCAMM is "low-power compression attached memory module", I had always assumed that "LP" DDR RAM was simply optimized for low power by design and manufacturing to run at a lower voltage, it turns out that it is actually a different standard.!!!
Thankfully the review above you linked to uses a CPU that supports both DDR5 and LPDDR5 so it is up to the manufacturer. Sadly that manufacturer is HP, so naturally they gimped the laptop by using awful RAM (yes I am a cynic), LPDDR5-5600 CL46 (yes, 46, that isn't a typo), and yes 5600 when LPDDR5 standard officially maxxes out at 6400, and of course they could have used DDR5 if they really wanted to, but they didn't even allow the CPU to hit it's maximum frequency, so max performance was never their goal here.
As for Samsung's LPCAMM, it will be using Samsung's very own LPDDR5X and can run up to 8533 speeds and use 20% less power than LPDDR5 (Wikipedia), so sounds promising if they can also get half decent latencies, doubly helped if the end product isn't made by HP :D
First of all, that huge L3 is only really beneficial with very high end GPU's running at lower resolution. Not really the most common combination.
Second, no one ever thought adding more cache on top of a chip was a cheap job. At least it's something added together with that added cost, unlike just simple binning.
"a money-making racket" --> A 60 dollar difference is a money-making racket? Such drama. How much must the GPU cost anyway in order to make that choice of CPU sensible? 60 is nothing..
And I don't care about the launch price, as no one is forced to buy at that point in time. Simple as that.
Your reasoning would only make sense if all high end users would benefit from all that L3, which isn't true.
GamingLeaksAndRumours/comments/pke49l/_/hc30xsk
No idea how these hacks get audience he's of the same cloth as Adored.
Ah no it doesn't, watch the video more closely, 15% is even Tom's own bottom of the range estimate. He already showed how conservative MD is with it's claims and why would they advertise the real figures so far ahead of time to Intel.
You would think that a person who does this for a living and does not hide behind a stupid anime profile picture and has actual sources is as close to professional as it gets.
Actual uplift is closer to 29%...
AMD have a history of sandbagging like crazy with Zen.
Also nT and 1T uplift can be different depending on SMT efficiency.
There is a difference in someone who lacks knowledge, misunderstoods, misrepresents or even misremembers something, vs. someone who intentionally lies (sometimes pathologically). Once you've identified a pattern of lies, you can safely assume that most of what that person is claiming to be untrue, and you should stop listening to that person. In some cases (I'm not referring to specific persons here), there might even be some kind of underlying condition, and it's useful for anyone to learn how to identify this. This goes not only for people online, but even more-so people in real life, like family, friends and colleagues. This is life advice for everyone; Don't let anyone manipulate you. :)
In terms of tech rumors, there are many "leakers" on Youtube, and some on various forums too. Some have been known to delete posts/videos once they've been proven embarrassingly wrong, I've seen this myself in the past based on my own notes, but I'm not going to say which "leakers" it is. Someone who cares more about this than me should download the videos and keep for evidence later.
But most of all, as I've been saying for years, people need to use some kind of "sniff test" on any rumor, and if it doesn't pass, then you can pretty safely assume it's BS.
Just consider the following;
CPUs and GPUs are many years in the making, Intel/AMD/Nvidia have multiple generations in various stages of development at any time, a major architecture can take ~5+ years and a minor one ~3 years to market. Major design features are decided firsts, followed by minor ones, followed by tweaks and adjustments. The closer to you are to a product launch, the more unlikely it is to do changes, as any change might add up to years of development time. By the time a product reaches tapeout, usually ~1-1.5 years ahead of intended launch, the design is complete, anything beyond that point are bugfixes or adjustments for yields etc.
Armed with this knowledge, I can say e.g. the rumors of Intel considering whether to have SMT-4 or no SMT for Arrow Lake was allegedly decided before this summer is absolutely nonsense. Such a change would impact every design decision throughout the microarchitecture, and would have been made in the very early stages of development. And the same goes for AMD rumors, whenever you hear claims of AMD making "last minute" design decisions.
As to what someone earlier mentioned, there are certainly industrial espionage going on too, in addition to streams of employees flowing between the companies, cooperation between them, lots of research published by universities and even some public speeches etc. All of which will let those who know the field use logical deduction to sense where the industry is heading. Some even have developer contacts which may give them some hints. This is why someone can make fairly accurate predictions, but these people are usually very clear about it being qualified guesses, not "I have 20 sources at AMD". And such predictions rarely result in specific features, performance figures etc. for particular CPUs/GPUs.