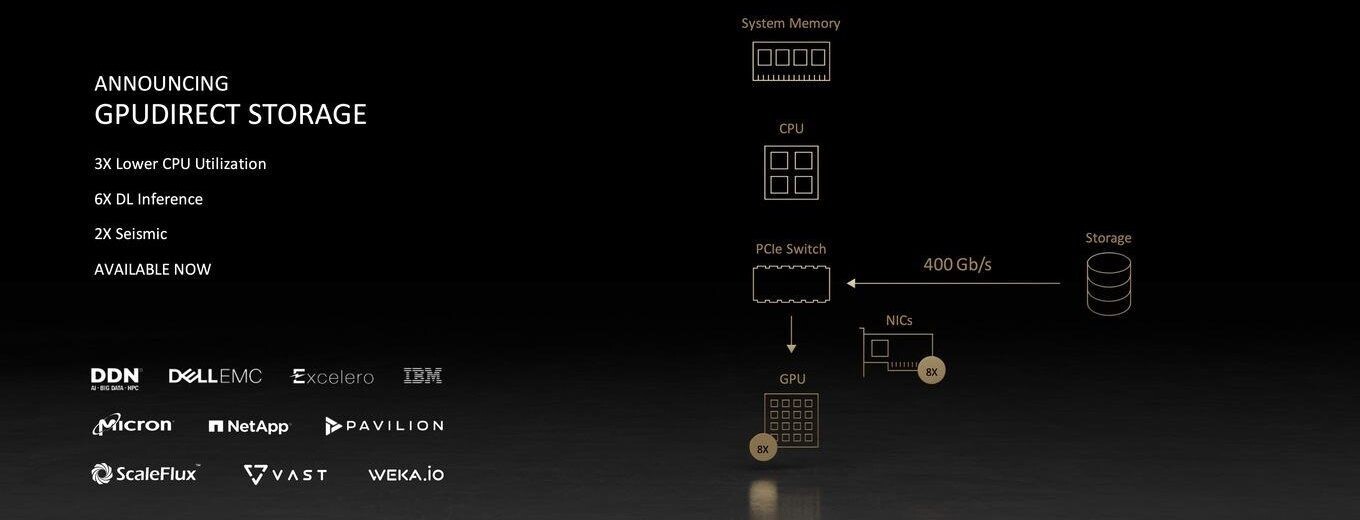
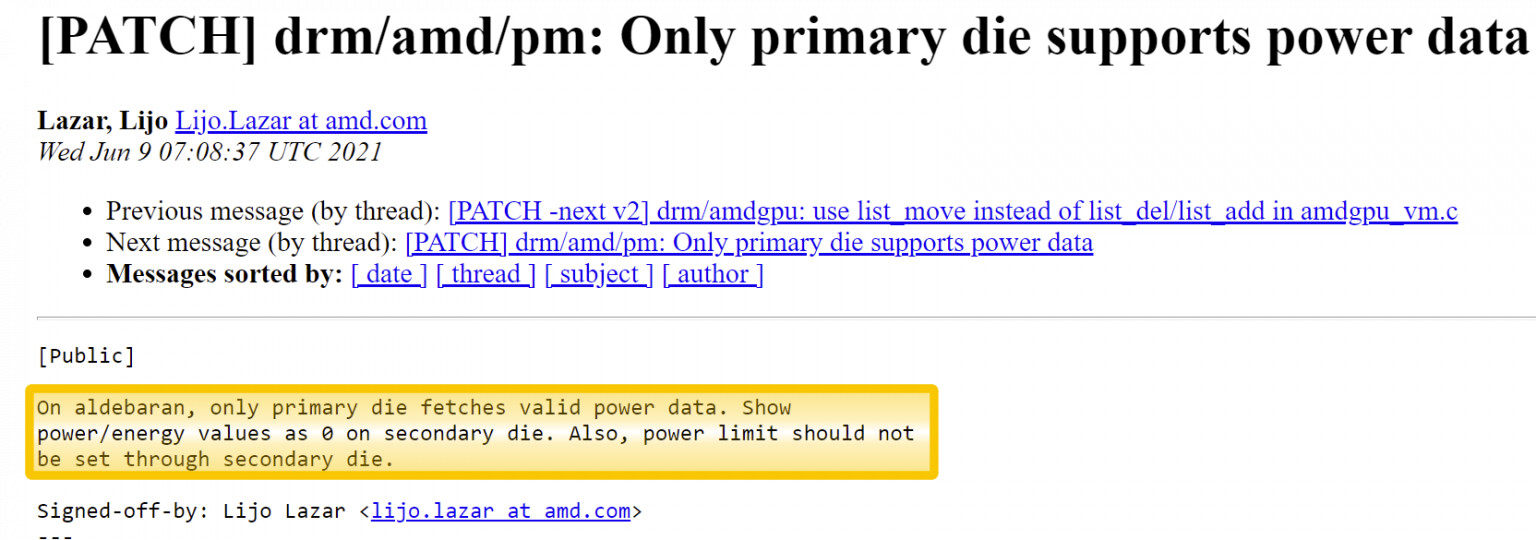
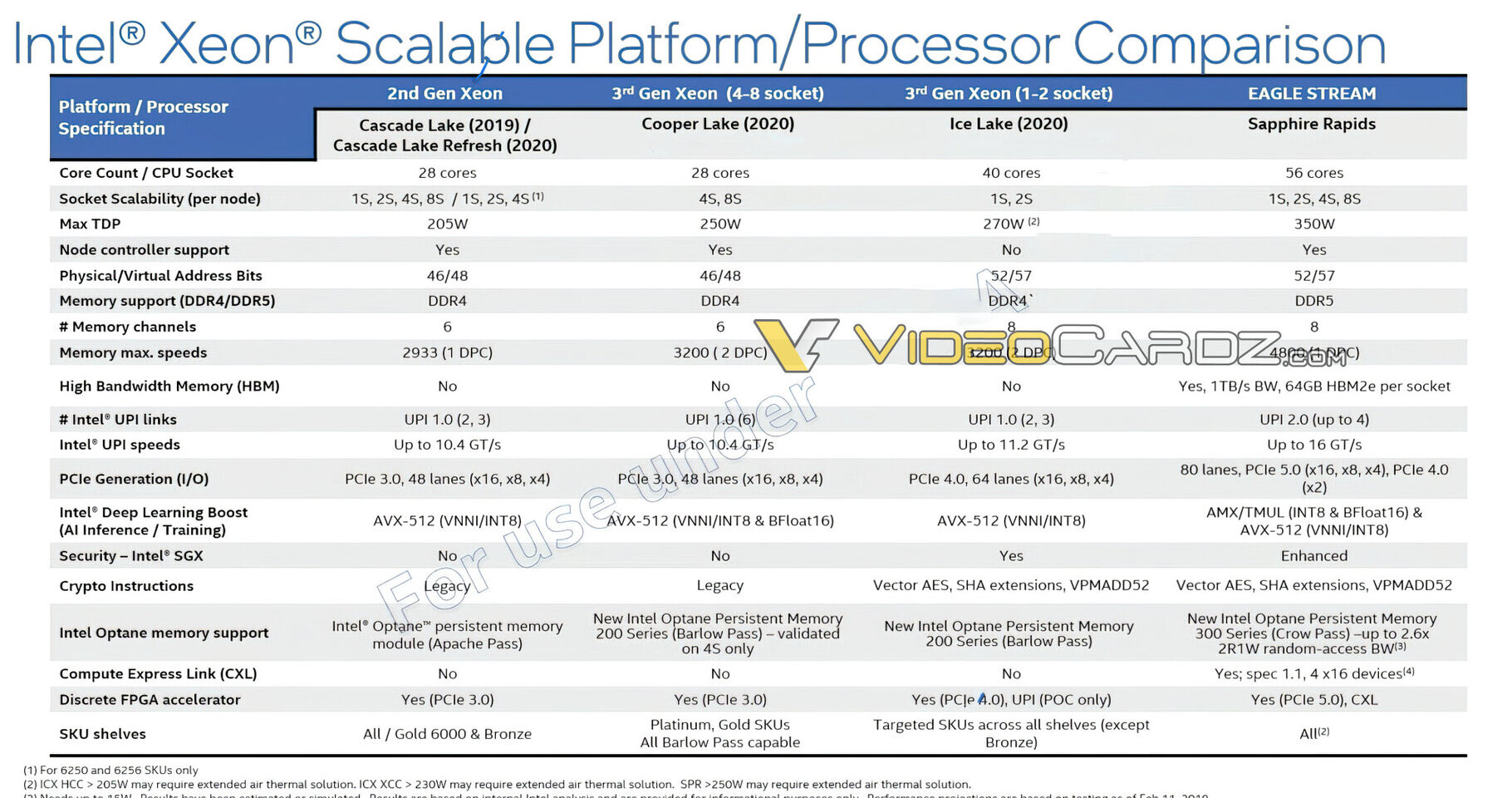
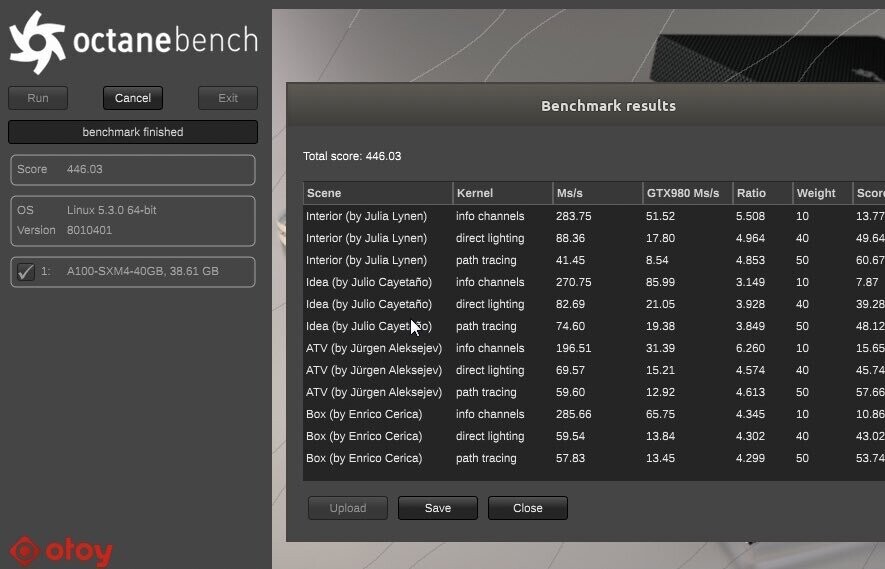
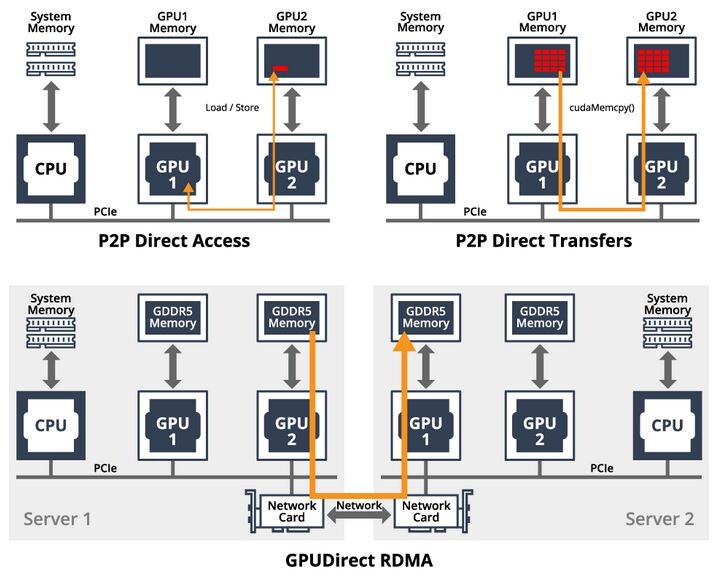
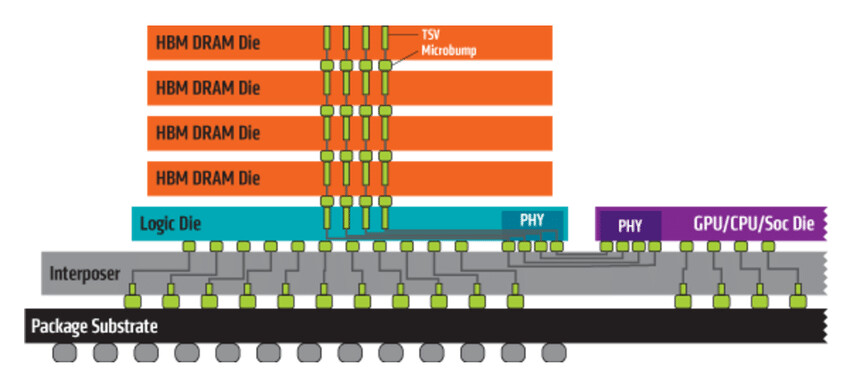
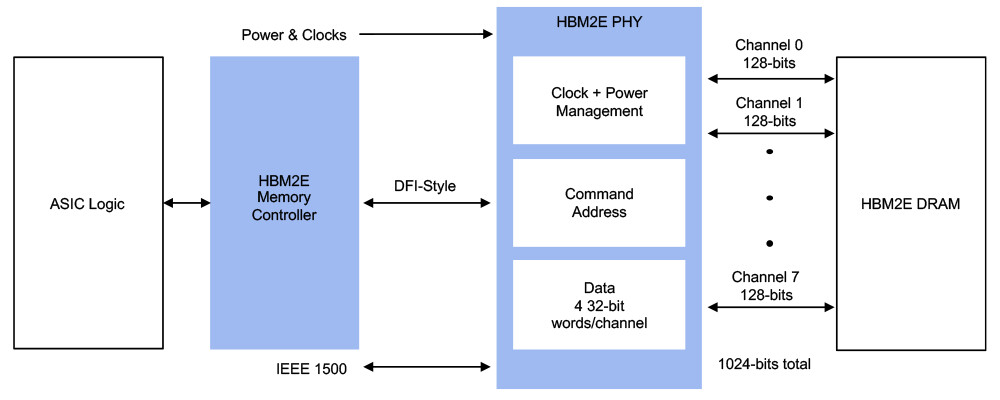
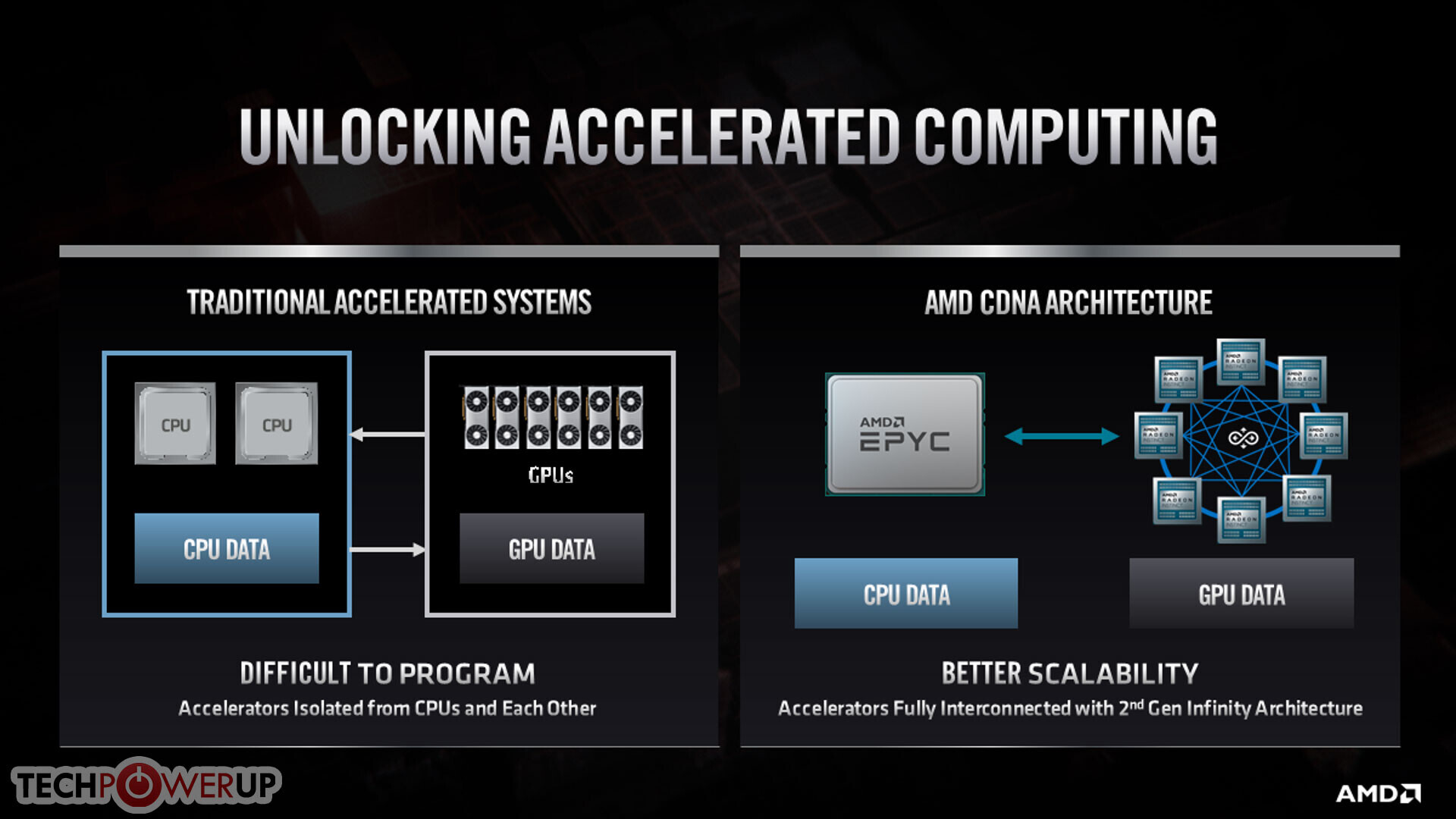
AMD BC-160 Cryptocurrency Mining Card Surfaces with 72 MH/s in ETH
VideoCardz has recently published pictures of a rumored AMD BC-160 (Blockchain Compute) mining card designed by XFX China and featuring a Navi 12 GPU. The card supposedly features 8 GB of HBM2 memory along with 2304 Stream Processors however a memory speed of 4 Gbps is also listed which is not currently available casting doubt on the legitimacy of this rumor. We did report on rumors in March that pointed to AMD releasing Navi 10/12 headless cryptocurrency mining cards so this could still be true.
The only existing product featuring the Navi 12 GPU is the Apple-exclusive AMD Radeon Pro 5600M which features 256 more Stream Processors at 2560. The BC-160 card was pictured in a mining cluster where it reached performance levels of 72 Mh/s in Etash with a TGP of 150 W. The card features two 8-pin power connectors and should offer performance around 25% faster than the Navi 10 Radeon RX 5700 XT. We are unsure if this is a real product or how much it might cost so take these rumors with a healthy dose of skepticism.

The only existing product featuring the Navi 12 GPU is the Apple-exclusive AMD Radeon Pro 5600M which features 256 more Stream Processors at 2560. The BC-160 card was pictured in a mining cluster where it reached performance levels of 72 Mh/s in Etash with a TGP of 150 W. The card features two 8-pin power connectors and should offer performance around 25% faster than the Navi 10 Radeon RX 5700 XT. We are unsure if this is a real product or how much it might cost so take these rumors with a healthy dose of skepticism.