Thursday, June 18th 2020

Intel Announces "Cooper Lake" 4P-8P Xeons, New Optane Memory, PCIe 4.0 SSDs, and FPGAs for AI
Intel today introduced its 3rd Gen Intel Xeon Scalable processors and additions to its hardware and software AI portfolio, enabling customers to accelerate the development and use of AI and analytics workloads running in data center, network and intelligent-edge environments. As the industry's first mainstream server processor with built-in bfloat16 support, Intel's new 3rd Gen Xeon Scalable processors makes artificial intelligence (AI) inference and training more widely deployable on general-purpose CPUs for applications that include image classification, recommendation engines, speech recognition and language modeling.
"The ability to rapidly deploy AI and data analytics is essential for today's businesses. We remain committed to enhancing built-in AI acceleration and software optimizations within the processor that powers the world's data center and edge solutions, as well as delivering an unmatched silicon foundation to unleash insight from data," said Lisa Spelman, Intel corporate vice president and general manager, Xeon and Memory Group.



 AI and analytics open new opportunities for customers across a broad range of industries, including finance, healthcare, industrial, telecom and transportation. IDC predicts that by 2021, 75% of commercial enterprise apps will use AI1. And by 2025, IDC estimates that roughly a quarter of all data generated will be created in real time, with various internet of things (IoT) devices creating 95% of that volume growth.
AI and analytics open new opportunities for customers across a broad range of industries, including finance, healthcare, industrial, telecom and transportation. IDC predicts that by 2021, 75% of commercial enterprise apps will use AI1. And by 2025, IDC estimates that roughly a quarter of all data generated will be created in real time, with various internet of things (IoT) devices creating 95% of that volume growth.
Unequaled Portfolio Breadth and Ecosystem Support for AI and Analytics
Intel's new data platforms, coupled with a thriving ecosystem of partners using Intel AI technologies, are optimized for businesses to monetize their data through the deployment of intelligent AI and analytics services.
Enhanced Intel Select Solutions Portfolio Address IT's Top Requirements: Intel has enhanced its Select Solutions portfolio to accelerate deployment of IT's most urgent requirements highlighting the value of pre-verified solution delivery in today's rapidly evolving business climate. Announced today are 3 new and 5 enhanced Intel Select Solutions focused on analytics, AI and hyper-converged infrastructure. The enhanced Intel Select Solution for Genomics Analytics is being used around the world to find a vaccine for COVID-19 and the new Intel Select Solution for VMware Horizon VDI on vSAN is being used to enhance remote learning.
The 3rd Gen Intel Xeon Scalable processors and Intel Optane persistent memory 200 series are shipping to customers today. In May, Facebook announced that 3rd Gen Intel Xeon Scalable processors are the foundation for its newest Open Compute Platform (OCP) servers, and other leading CSPs, including Alibaba, Baidu and Tencent, have announced they are adopting the next-generation processors. General OEM systems availability is expected in 2H 2020. The Intel SSD D7-P5500 and P5600 3D NAND SSDs are available today. And the Intel Stratix 10 NX FPGA is expected to be available in the 2H 2020.


Complete Slide Deck








































"The ability to rapidly deploy AI and data analytics is essential for today's businesses. We remain committed to enhancing built-in AI acceleration and software optimizations within the processor that powers the world's data center and edge solutions, as well as delivering an unmatched silicon foundation to unleash insight from data," said Lisa Spelman, Intel corporate vice president and general manager, Xeon and Memory Group.





Unequaled Portfolio Breadth and Ecosystem Support for AI and Analytics
Intel's new data platforms, coupled with a thriving ecosystem of partners using Intel AI technologies, are optimized for businesses to monetize their data through the deployment of intelligent AI and analytics services.
- New 3rd Gen Intel Xeon Scalable Processors: Intel is further extending its investment in built-in AI acceleration in the new 3rd Gen Intel Xeon Scalable processors through the integration of bfloat16 support into the processor's unique Intel DL Boost technology. bfloat16 is a compact numeric format that uses half the bits as today's FP32 format but achieves comparable model accuracy with minimal (if any) software changes required. The addition of bfloat16 support accelerates both AI training and inference performance in the CPU. Intel-optimized distributions for leading deep learning frameworks (including TensorFlow and Pytorch) support bfloat16 and are available through the Intel AI Analytics toolkit. Intel also delivers bfloat16 optimizations into its OpenVINO toolkit and the ONNX Runtime environment to ease inference deployments.
- The 3rd Gen Intel Xeon Scalable processors (codenamed "Cooper Lake") evolve Intel's 4- and 8-socket processor offering. The processor is designed for deep learning, virtual machine (VM) density, in-memory database, mission-critical applications and analytics-intensive workloads. Customers refreshing aging infrastructure can expect an average estimated gain of 1.9x on popular workloads and up to 2.2x more VMs compared with 5-year-old, 4-socket platform equivalents.
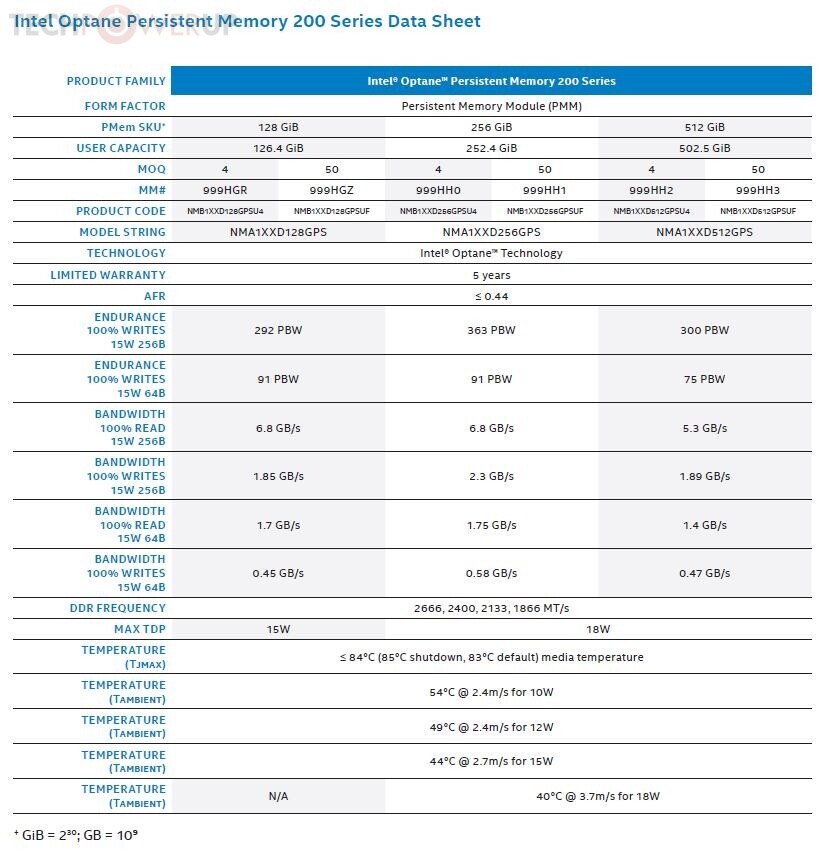
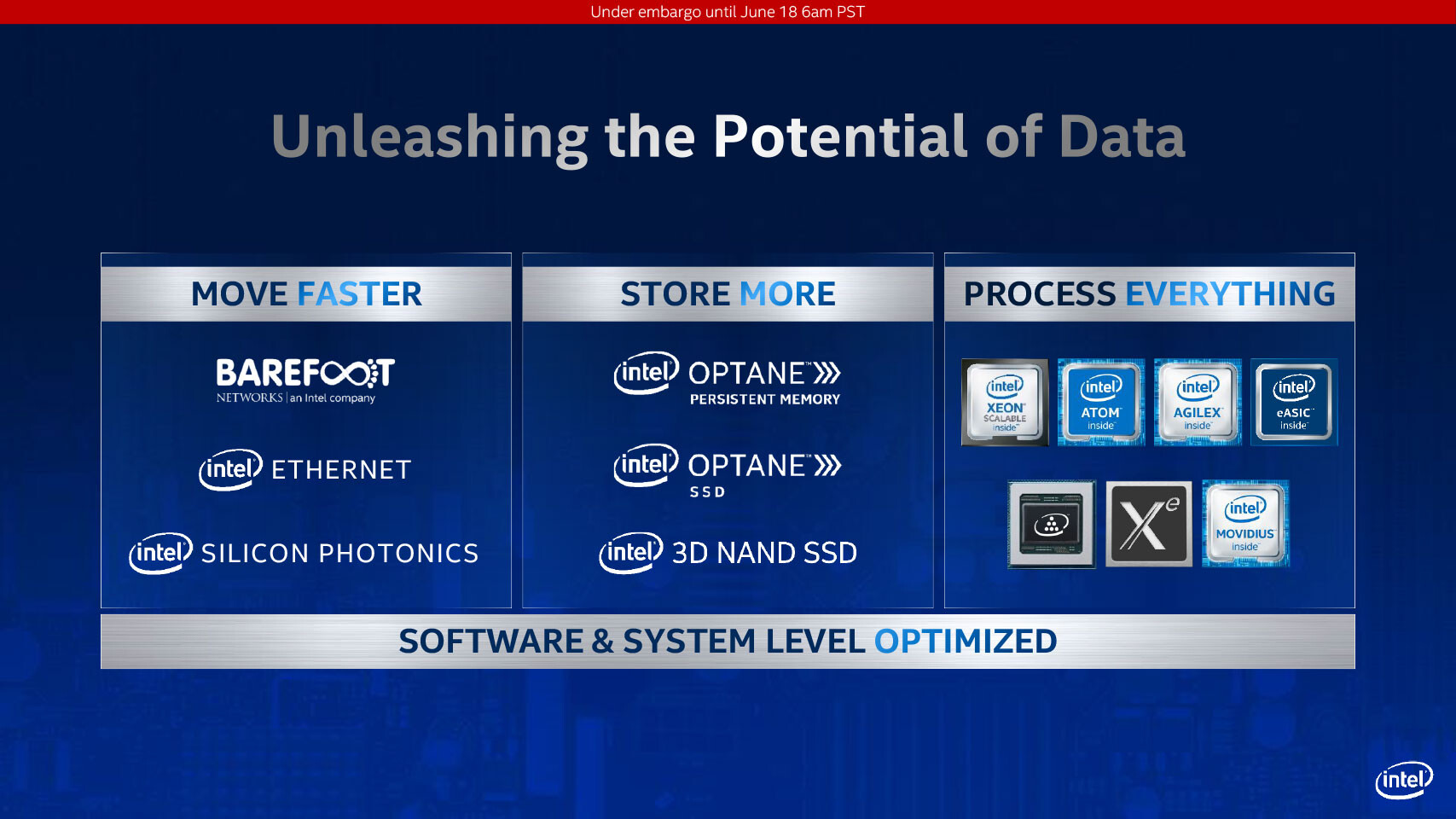
- New Intel Optane Persistent Memory: As part of the 3rd Gen Intel Xeon Scalable platform, the company also announced the Intel Optane persistent memory 200 series, providing customers up to 4.5 TB of memory per socket to manage data intensive workloads, such as in-memory databases, dense virtualization, analytics and high-powered computing.
- New Intel 3D NAND SSDs: For systems that store data in all-flash arrays, Intel announced the availability of its next-generation high-capacity Intel 3D NAND SSDs, the Intel SSD D7-P5500 and P5600. These 3D NAND SSDs are built with Intel's latest triple-level cell (TLC) 3D NAND technology and an all-new low-latency PCIe controller to meet the intense IO requirements of AI and analytics workloads and advanced features to improve IT efficiency and data security.
- First Intel AI-Optimized FPGA: Intel disclosed its upcoming Intel Stratix 10 NX FPGAs, Intel's first AI-optimized FPGAs targeted for high-bandwidth, low-latency AI acceleration. These FPGAs will offer customers customizable, reconfigurable and scalable AI acceleration for compute-demanding applications such as natural language processing and fraud detection. Intel Stratix 10 NX FPGAs include integrated high-bandwidth memory (HBM), high-performance networking capabilities and new AI-optimized arithmetic blocks called AI Tensor Blocks, which contain dense arrays of lower-precision multipliers typically used for AI model arithmetic.
Enhanced Intel Select Solutions Portfolio Address IT's Top Requirements: Intel has enhanced its Select Solutions portfolio to accelerate deployment of IT's most urgent requirements highlighting the value of pre-verified solution delivery in today's rapidly evolving business climate. Announced today are 3 new and 5 enhanced Intel Select Solutions focused on analytics, AI and hyper-converged infrastructure. The enhanced Intel Select Solution for Genomics Analytics is being used around the world to find a vaccine for COVID-19 and the new Intel Select Solution for VMware Horizon VDI on vSAN is being used to enhance remote learning.
The 3rd Gen Intel Xeon Scalable processors and Intel Optane persistent memory 200 series are shipping to customers today. In May, Facebook announced that 3rd Gen Intel Xeon Scalable processors are the foundation for its newest Open Compute Platform (OCP) servers, and other leading CSPs, including Alibaba, Baidu and Tencent, have announced they are adopting the next-generation processors. General OEM systems availability is expected in 2H 2020. The Intel SSD D7-P5500 and P5600 3D NAND SSDs are available today. And the Intel Stratix 10 NX FPGA is expected to be available in the 2H 2020.









































13 Comments on Intel Announces "Cooper Lake" 4P-8P Xeons, New Optane Memory, PCIe 4.0 SSDs, and FPGAs for AI
That is innovation..
And funny how they haven’t got any charts comparing them to Epyc/Rome.
And New Optane PCIe 4.0 SSDs with the gen 2 controllers?
Those, the more pertinent questions for simple builders like us. :)
Actually, there are two Os and one P instead of the other way around.
libraries and obfuscation of calculation.
BF16 is often not used singularly and exclusively, but is mixed with FP32 in an ad hoc fashion, to obtain speed gains. Look, says the coder, i gained 30% throughput by optimising the algorithm using BF32 on the multipliers. Great, lets bake that into production.
years later, libraries layered on layers, API’s linked over networks or Internet, some IMPORTANT application will use one of these now standard libraries and deliver most of the time Accurate results but sometimes inaccurate results that could havemajor consequences, and the developer or user is Non the wiser and things will go wrong. Security? financial markets? Rocket trajectories? www.bbc.com/future/article/20150505-the-numbers-that-lead-to-disaster
Einstein said Everything should be made as simple as possible, but not simpler. There is a huge risk BF16 will be tomorrows year 2000 problem, or The GPS rollover problem, or other examples. We will regret it, it if gets out of its special case box
Neural networks are never "accurate" no matter the floating point precision, they can't be by definition, they are statistical models.