Monday, July 11th 2022

NVIDIA PrefixRL Model Designs 25% Smaller Circuits, Making GPUs More Efficient
When designing integrated circuits, engineers aim to produce an efficient design that is easier to manufacture. If they manage to keep the circuit size down, the economics of manufacturing that circuit is also going down. NVIDIA has posted on its technical blog a technique where the company uses an artificial intelligence model called PrefixRL. Using deep reinforcement learning, NVIDIA uses the PrefixRL model to outperform traditional EDA (Electronics Design Automation) tools from major vendors such as Cadence, Synopsys, or Siemens/Mentor. EDA vendors usually implement their in-house AI solution to silicon placement and routing (PnR); however, NVIDIA's PrefixRL solution seems to be doing wonders in the company's workflow.
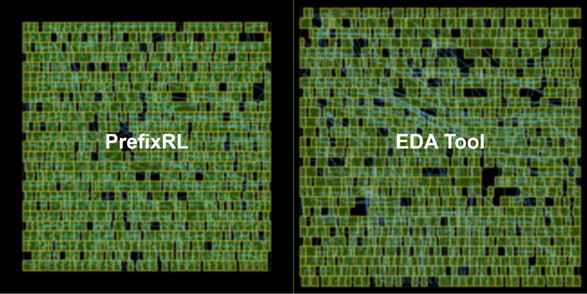
Creating a deep reinforcement learning model that aims to keep the latency the same as the EDA PnR attempt while achieving a smaller die area is the goal of PrefixRL. According to the technical blog, the latest Hopper H100 GPU architecture uses 13,000 instances of arithmetic circuits that the PrefixRL AI model designed. NVIDIA produced a model that outputs a 25% smaller circuit than comparable EDA output. This is all while achieving similar or better latency. Below, you can compare a 64-bit adder design made by PrefixRL and the same design made by an industry-leading EDA tool.
 Training such a model is a compute-intensive task. NVIDIA reports that the training to design a 64-bit adder circuit took 256 CPU cores for each GPU and 32,000 GPU hours. The company developed Raptor, an in-house distributed reinforcement learning platform that takes unique advantage of NVIDIA hardware for this kind of industrial reinforcement learning, which you can see below and how it operates. Overall, the system is pretty complex and requires a lot of hardware and input; however, the results pay off with smaller and more efficient GPUs.
Training such a model is a compute-intensive task. NVIDIA reports that the training to design a 64-bit adder circuit took 256 CPU cores for each GPU and 32,000 GPU hours. The company developed Raptor, an in-house distributed reinforcement learning platform that takes unique advantage of NVIDIA hardware for this kind of industrial reinforcement learning, which you can see below and how it operates. Overall, the system is pretty complex and requires a lot of hardware and input; however, the results pay off with smaller and more efficient GPUs.
Source:
NVIDIA
Creating a deep reinforcement learning model that aims to keep the latency the same as the EDA PnR attempt while achieving a smaller die area is the goal of PrefixRL. According to the technical blog, the latest Hopper H100 GPU architecture uses 13,000 instances of arithmetic circuits that the PrefixRL AI model designed. NVIDIA produced a model that outputs a 25% smaller circuit than comparable EDA output. This is all while achieving similar or better latency. Below, you can compare a 64-bit adder design made by PrefixRL and the same design made by an industry-leading EDA tool.


43 Comments on NVIDIA PrefixRL Model Designs 25% Smaller Circuits, Making GPUs More Efficient
In general, the problem of dividing a given surface into small pieces in an optimal way is NP-complete (en.wikipedia.org/wiki/NP-completeness), thus not something you want to/can tackle without some form of approximation or heuristic.
Yes I know R&D aint cheap, but this all sounds like just ANUTHA way to justify keeping GPU prices & profits at scalper/pandemic levels, which they have become addicted to like crackheads & their rocks... they always need/want moar and can't quit even if they wanted to....
Now that you've mentioned it, I'm starting to wonder why is enforcement learning a better fit than genetic algorithms. Start with a solution and mutate it till it gets significantly better. There's obviously an explanation for that (I'm not smarter than an entire department of engineers), I just don't know it.
A case of intuition playing tricks on us.If they're smart, they'll just split the difference.
I don't know, I just read the source (Nvidia):
«to the best of our knowledge, this is the first method using a deep reinforcement learning agent to design arithmetic circuits.»
AMD on 7nm - 51,3 Mtr/mm2
Nvidia on 7nm - 65,6 Mtr/mm2 4/5nm - 98,2 Mtr/mm2
i heard Raptor from AMD Gaming Evolved, oh wait ... no it was Raptr (and died in 2017 :laugh: )
oh, well, i guess a O more does not hurt :roll:
What I meant to say is that I am pretty certain, in some form or another, others also use some AI techniques in their product pipelines.
Then I started to function I drank my coffee...:banghead: