Friday, February 18th 2022

Intel "Meteor Lake" and "Arrow Lake" Use GPU Chiplets
Intel's upcoming "Meteor Lake" and "Arrow Lake" client mobile processors introduce an interesting twist to the chiplet concept. Earlier represented in vague-looking IP blocks, new artistic impressions of the chip put out by Intel shed light on a 3-die approach not unlike the Ryzen "Vermeer" MCM that has up to two CPU core dies (CCDs) talking to a cIOD (client IO die), which handles all the SoC connectivity; Intel's design has one major difference, and that's integrated graphics. Apparently, Intel's MCM uses a GPU die sitting next to the CPU core die, and the I/O (SoC) die. Intel likes to call its chiplets "tiles," and so we'll go with that.
The Graphics tile, CPU tile, and the SoC or I/O tile, are built on three different silicon fabrication process nodes based on the degree of need for the newer process node. The nodes used are Intel 4 (optically 7 nm EUV, but with characteristics of a 5 nm-class node); Intel 20A (characteristics of 2 nm), and external TSMC N3 (3 nm) node. At this point we don't know which tile gets what. From the looks of it, the CPU tile has a hybrid CPU core architecture made up of "Redwood Cove" P-cores, and "Crestmont" E-core clusters.
 The Graphics tile packs an iGPU based on the Xe LP graphics architecture, but leverages an advanced node to significantly increase the execution unit (EU) count to 352, and possible increase graphics clocks. The SoC and I/O tile packs the platform security processor, integrated northbridge, memory controllers, PCI-Express root-complex, and the various platform I/O.
The Graphics tile packs an iGPU based on the Xe LP graphics architecture, but leverages an advanced node to significantly increase the execution unit (EU) count to 352, and possible increase graphics clocks. The SoC and I/O tile packs the platform security processor, integrated northbridge, memory controllers, PCI-Express root-complex, and the various platform I/O.
Intel is preparing "Meteor Lake" for a 2023 launch, with development completing within 2022, although mass-production might still commence next year.
The Graphics tile, CPU tile, and the SoC or I/O tile, are built on three different silicon fabrication process nodes based on the degree of need for the newer process node. The nodes used are Intel 4 (optically 7 nm EUV, but with characteristics of a 5 nm-class node); Intel 20A (characteristics of 2 nm), and external TSMC N3 (3 nm) node. At this point we don't know which tile gets what. From the looks of it, the CPU tile has a hybrid CPU core architecture made up of "Redwood Cove" P-cores, and "Crestmont" E-core clusters.

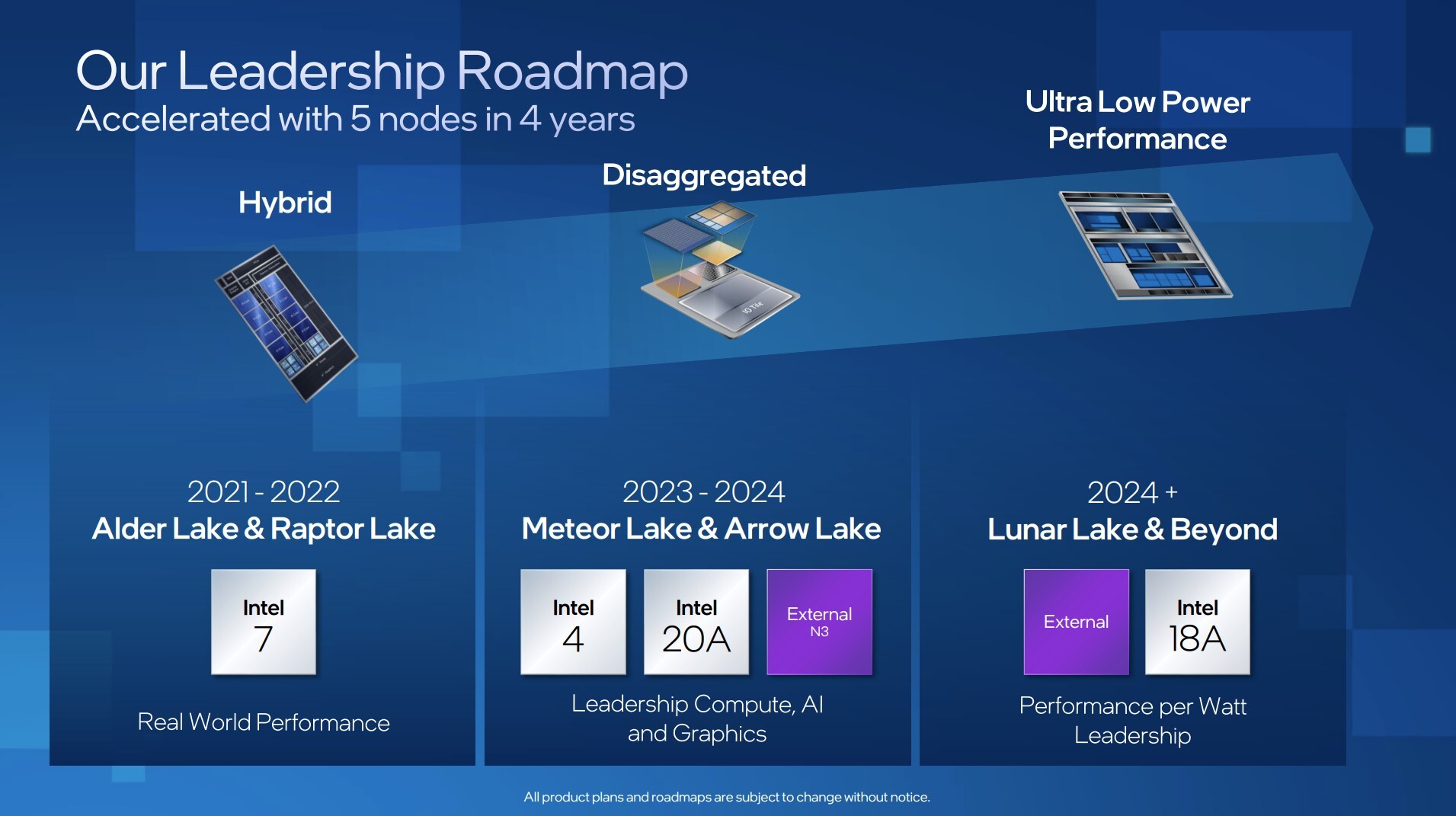
Intel is preparing "Meteor Lake" for a 2023 launch, with development completing within 2022, although mass-production might still commence next year.
36 Comments on Intel "Meteor Lake" and "Arrow Lake" Use GPU Chiplets
And a few weeks ago they were buying their competitors GPU to place on their McM.(sarcasm :p)
In fact the only new bit is Intel has decided to nick AMD'S McM IO die concept, no?!.
The CPU die was based on a 32nm process while the iGPU die was 45nm.
en.wikipedia.org/wiki/Clarkdale_(microprocessor)
What is the interface between the tiles on these?
"The nodes used are Intel 4 (optically 7 nm EUV, but with characteristics of a 5 nm-class node)...."
I like what you did w this one. Achieved third-tier BS, you have. 7/10.
Stay classy, armchair TPU engineers.
Combining different IPs from different nodes together to work as if it was a monolithic design has the bandwidth advantage to it. That means more data per per given time frame.
And Intel's way of doing Emib certainly differs from anyone else's.
I too think that it's going to be very good but let's wait and see how it performs in Sapphire Rapids. It's supposed to integrate the four chips so tightly as to make any interface logic unnecessary. It would result in lower latency but lower power consumption is equally important.
Here's a delidded Westmere CPU, an X5690, from early 2011.
I think Clarkdale did have issues with latency.
Didn't Zen 2 also have issues with latency between the different core clusters?
EDIT: Apparently the old Core 2 Quads had multiple dies.
Picture from @Ruslan
I knew that the older Pentium D chips also had multiple dies.
Both dies were processor dies. This was back in the days of having the northbridge on the motherboard.
No concrete info on how exactly this technology is going to work.
And then recently die on die Stiction pads.
chipsetstiles?