Wednesday, May 8th 2024

Core Configurations of Intel Core Ultra 200 "Arrow Lake-S" Desktop Processors Surface
Intel is giving its next-generation desktop processor lineup the Core Ultra 200 series processor model numbering. We detailed the processor numbering in our older report. The Core Ultra 200 series would be the company's first desktop processors with AI capabilities thanks to an integrated 50 TOPS-class NPU. At the heart of these processors is the "Arrow Lake" microarchitecture. Its development is the reason the company had to refresh "Raptor Lake" to cover its 2023-24 processor lineup. The company's "Meteor Lake" microarchitecture topped off at CPU core counts of 6P+8E, which would have proven to be a generational regression in multithreaded application performance over "Raptor Lake." The new "Arrow Lake-S" desktop processor has a maximum CPU core configuration of 8P+16E, which means consumers can expect at least the same core-counts at given price-points to carry over.
According to a report by Chinese tech publication Benchlife.info, the introduction of "Arrow Lake" would see Intel's desktop processor model numbering align with that of its mobile processor numbering, and incorporate the Core Ultra brand to denote the latest microarchitecture for a given processor generation. Since "Arrow Lake" is a generation ahead of "Meteor Lake," processor models in the series get numbered under Core Ultra 200 series. Intel will likely debut the lineup with overclocker-friendly K and KF SKUs. The lineup is led by the Core Ultra 9 285K (and possibly the 285KF), which comes with an 8P+16E core configuration, a processor base power value of 125 W, and a maximum P-core boost frequency of 5.50 GHz. This is followed by the Core Ultra 7 265K (and 265KF), with an 8P+12E core configuration; and the Core Ultra 5 245K, with a 6P+8E core-configuration.
Intel will likely debut the lineup with overclocker-friendly K and KF SKUs. The lineup is led by the Core Ultra 9 285K (and possibly the 285KF), which comes with an 8P+16E core configuration, a processor base power value of 125 W, and a maximum P-core boost frequency of 5.50 GHz. This is followed by the Core Ultra 7 265K (and 265KF), with an 8P+12E core configuration; and the Core Ultra 5 245K, with a 6P+8E core-configuration.
There are also some 65 W non-K models in the middle, although these don't have similar processor model numbers to the K/KF parts. There's the Core Ultra 9 275 (8P+16E, 65 W); the Core Ultra 7 255 (8P+12E, 65 W); and the Core Ultra 5 240 (6P+4E, 65 W).
"Arrow Lake" is a chiplet-based processor, just like "Meteor Lake." Its compute tile, the piece of silicon with the CPU cores, packs up to 8 "Lion Cove" performance cores (P-cores), and up to 16 "Skymont" efficiency cores (E-cores). The processor is also expected to feature a 50 TOPS-class NPU for on-device AI acceleration, and a truncated version of the Xe-LPG iGPU the company is using with "Meteor Lake," which could be branded differently from the Arc Graphics branding Intel is using on the Core Ultra 100 series mobile chips. "Arrow Lake" is also expected to debut a new CPU socket on the desktop platform, the LGA1851, with more I/O capabilities than the LGA1700 and "Raptor Lake."
Sources:
BenchLife, VideoCardz
According to a report by Chinese tech publication Benchlife.info, the introduction of "Arrow Lake" would see Intel's desktop processor model numbering align with that of its mobile processor numbering, and incorporate the Core Ultra brand to denote the latest microarchitecture for a given processor generation. Since "Arrow Lake" is a generation ahead of "Meteor Lake," processor models in the series get numbered under Core Ultra 200 series.
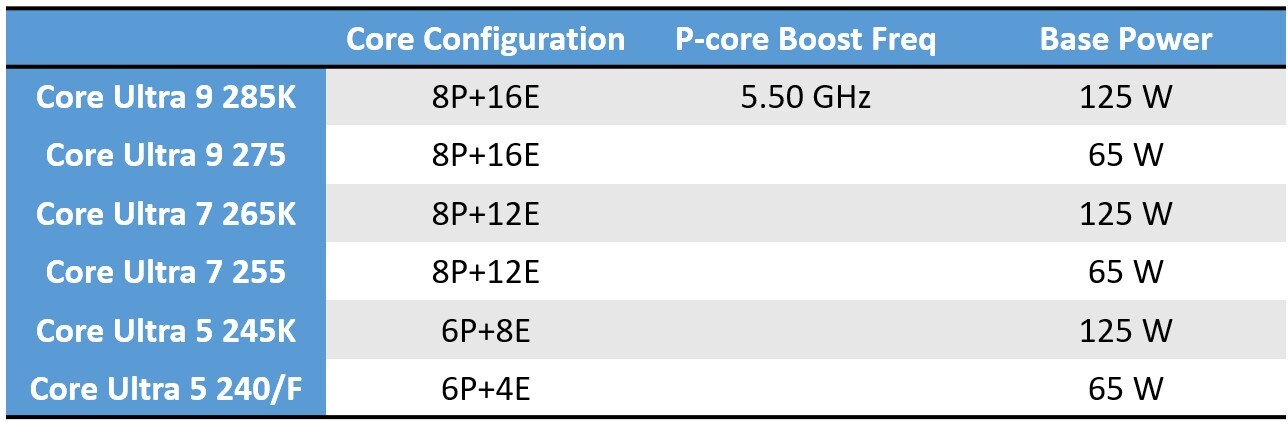
There are also some 65 W non-K models in the middle, although these don't have similar processor model numbers to the K/KF parts. There's the Core Ultra 9 275 (8P+16E, 65 W); the Core Ultra 7 255 (8P+12E, 65 W); and the Core Ultra 5 240 (6P+4E, 65 W).
"Arrow Lake" is a chiplet-based processor, just like "Meteor Lake." Its compute tile, the piece of silicon with the CPU cores, packs up to 8 "Lion Cove" performance cores (P-cores), and up to 16 "Skymont" efficiency cores (E-cores). The processor is also expected to feature a 50 TOPS-class NPU for on-device AI acceleration, and a truncated version of the Xe-LPG iGPU the company is using with "Meteor Lake," which could be branded differently from the Arc Graphics branding Intel is using on the Core Ultra 100 series mobile chips. "Arrow Lake" is also expected to debut a new CPU socket on the desktop platform, the LGA1851, with more I/O capabilities than the LGA1700 and "Raptor Lake."
101 Comments on Core Configurations of Intel Core Ultra 200 "Arrow Lake-S" Desktop Processors Surface
Also SMT/HT has it's own issues, There are a lot of ways to implement it and they are not equal in terms of performance and transistor budget. Take a look at this article which comments on how the structures can be replicated for SMT
chipsandcheese.com/2024/03/13/loongson-3a6000-a-star-among-chinese-cpus/comment-page-1/
Which the tl;dr is Statically Partioned(each thread gets a static portion of structure), Duplicated, Watermark(each thread can have up to X of resources) and Competitively Shared.
As an example, supposed you have a Core with 96 Physical Registers and two threads. How are you doing to handle it? If you assign 48 physical registers to each then you are reducing the IPC of the thread in general, it can have moments where it could have used more registers but it didn't have them while the other thread is inactive. Watermark and Competitively Shared solve that, but they are much more complex and take more transistors.
Not only that but they might also become harder to implement as the structure sizes (and other related things) increases. As an example, supposed you want to add another write port to the register file as you noticed that things were stalling due to lack of those, you will likely need to add a lot more transistor so it can run the Competitively Shared stuff.
This might mean that HT for Intel had reached such proportions that they thought that the advantages that it brings isn't enough for the drawbacks. A lot of chip designers like ARM and Apple have never used HT/SMT and their designs are very competitive.
In some cases, HT/SMT works really well and is basically a 'free performance boost' like with Pentium 4s where issues with the pipeline might have meant a lot of resources went unused. Or for situations where maximum threads is the objective like for Cloud, as the client pays for vCPU, so more threads = more vCPUs to sell(hence why IBM does 4-way or 8-way SMT).
That means the first thread cannot utilize all the resources available.Why it can't be?
Moving the memory controller out for the die, for example, will lower the IPC.
I'm also not sure I would extrapolate the current MTL interconnect behaviour to anything desktop in the future. There are significant differences in the way Ryzen mobile handles Fabric clock behaviour vs desktop - MTL seems to signal Intel heading in that direction as well.
MTL has outstanding idle package power in some designs, on par with monolithic -U and -P, so certainly the uncore behaviour is all round tailored to achieve that result.
If it's at least a substantial (a leap was used previously..) overall improvement over last gen!
You can remove core functionality anytime resulting in app performance drops. These drops are factored into median app performance or IPC.
I'm aware of the SPEC testing that all the outlets reported on, but not too keen on the testing methodology there. Not much has been said about how the author verified actual clocks during test of any of the parts (did he just divide by advertised boost clocks?), and I think it rather clear from knowledge elsewhere and from his own results that SPEC 2017 is significantly more cache and memory intensive than he admits. Seeing as memory subsystem is completely apples to oranges, seems to be kinda important.
Just saying that "LPDDR5 vs. DDR5 shouldn't have much effect" is pretty bizarre. LPDDR performance is anything but great, it's just games that have recently put it in a favourable light since iGPUs like the bandwidth it provides while caring less about timings and latency. While I'm sure he made do with what he had (hard to have fair comparisons in laptops), it doesn't mean the results necessarily have any significance.
micro-ops(decode + uop cache) from 11 to 11 +0%
Dispatch/Rename from 4 to 5 +25%
execution ports from 8 to 10 +25%
With 2xFP/ALU + 2xALU, 1xS/D + 3xAGU
for 3xFP/ALU + 1xALU, 2xS/D + 4xAGU
IPC average +18%
SunnyCove - GoldenCove
micro-ops(decode + uop cache) from 11 to 14 +27%
Dispatch/Rname from 5 to 6 +20%
execution ports from 10 to 12 +20%
With 3xFP/ALU + 1xALU, 2xS/D + 4xAGU
for 3xFP/ALU + 2xALU, 2xS/D + 5xAGU
FPU+ALU from 4 to 5 +25%
IPC average +19%
GoldenCove - LionCove
micro-ops(decode + uop cache) from 14 to 24 +71.4%
Dispatch/Rename from 6 to 8 +33.3%
execution ports from 12 to 18 +50%
With 3xFP/ALU + 2xALU, 2xS/D + 5xAGU
up to 4xFPU, 6xALU, 2xS/D + 6xAGU
FPU+ALU from 5 to 10 +100%
IPC average +??%
Two different diagrams of the LionCove core from LunarLake graphics:
LionCove introduces a larger scale redesign and expansion than previously SunnyCove to Skylake and GoldenCove to SunnyCove. I don't know how much of an increase in IPC this will give, but I have a feeling that it will be more than what the current leaks say.
ArrowLake is based on LionCove and Skymont cores.
Skymont has a 3x 3-way(9-Way) decoder, while Gracemont has a 2x 3-way(6-Way) decoder, which is an increase of 50%.
LionCove core:
Intel always represents the Predictor as one block in the diagram. In the case of LionCove it looks like 4 Tier or 4-Way.
LionCove has 24 ops from the decoder and uop cache. GoldenCobe has 14 uops (6 from the decoder and 8 from the uop cache). LionCove has an 8-10-Way and 16-14 decoder with uop cache.
Zen 5 non-x3d will probably be on par with 7800x3D so for gaming nothing really is going to change, on the MT side you're right tho that 9950X will mop up the floor with the 14900k.