Wednesday, May 8th 2024

Core Configurations of Intel Core Ultra 200 "Arrow Lake-S" Desktop Processors Surface
Intel is giving its next-generation desktop processor lineup the Core Ultra 200 series processor model numbering. We detailed the processor numbering in our older report. The Core Ultra 200 series would be the company's first desktop processors with AI capabilities thanks to an integrated 50 TOPS-class NPU. At the heart of these processors is the "Arrow Lake" microarchitecture. Its development is the reason the company had to refresh "Raptor Lake" to cover its 2023-24 processor lineup. The company's "Meteor Lake" microarchitecture topped off at CPU core counts of 6P+8E, which would have proven to be a generational regression in multithreaded application performance over "Raptor Lake." The new "Arrow Lake-S" desktop processor has a maximum CPU core configuration of 8P+16E, which means consumers can expect at least the same core-counts at given price-points to carry over.
According to a report by Chinese tech publication Benchlife.info, the introduction of "Arrow Lake" would see Intel's desktop processor model numbering align with that of its mobile processor numbering, and incorporate the Core Ultra brand to denote the latest microarchitecture for a given processor generation. Since "Arrow Lake" is a generation ahead of "Meteor Lake," processor models in the series get numbered under Core Ultra 200 series. Intel will likely debut the lineup with overclocker-friendly K and KF SKUs. The lineup is led by the Core Ultra 9 285K (and possibly the 285KF), which comes with an 8P+16E core configuration, a processor base power value of 125 W, and a maximum P-core boost frequency of 5.50 GHz. This is followed by the Core Ultra 7 265K (and 265KF), with an 8P+12E core configuration; and the Core Ultra 5 245K, with a 6P+8E core-configuration.
Intel will likely debut the lineup with overclocker-friendly K and KF SKUs. The lineup is led by the Core Ultra 9 285K (and possibly the 285KF), which comes with an 8P+16E core configuration, a processor base power value of 125 W, and a maximum P-core boost frequency of 5.50 GHz. This is followed by the Core Ultra 7 265K (and 265KF), with an 8P+12E core configuration; and the Core Ultra 5 245K, with a 6P+8E core-configuration.
There are also some 65 W non-K models in the middle, although these don't have similar processor model numbers to the K/KF parts. There's the Core Ultra 9 275 (8P+16E, 65 W); the Core Ultra 7 255 (8P+12E, 65 W); and the Core Ultra 5 240 (6P+4E, 65 W).
"Arrow Lake" is a chiplet-based processor, just like "Meteor Lake." Its compute tile, the piece of silicon with the CPU cores, packs up to 8 "Lion Cove" performance cores (P-cores), and up to 16 "Skymont" efficiency cores (E-cores). The processor is also expected to feature a 50 TOPS-class NPU for on-device AI acceleration, and a truncated version of the Xe-LPG iGPU the company is using with "Meteor Lake," which could be branded differently from the Arc Graphics branding Intel is using on the Core Ultra 100 series mobile chips. "Arrow Lake" is also expected to debut a new CPU socket on the desktop platform, the LGA1851, with more I/O capabilities than the LGA1700 and "Raptor Lake."
Sources:
BenchLife, VideoCardz
According to a report by Chinese tech publication Benchlife.info, the introduction of "Arrow Lake" would see Intel's desktop processor model numbering align with that of its mobile processor numbering, and incorporate the Core Ultra brand to denote the latest microarchitecture for a given processor generation. Since "Arrow Lake" is a generation ahead of "Meteor Lake," processor models in the series get numbered under Core Ultra 200 series.
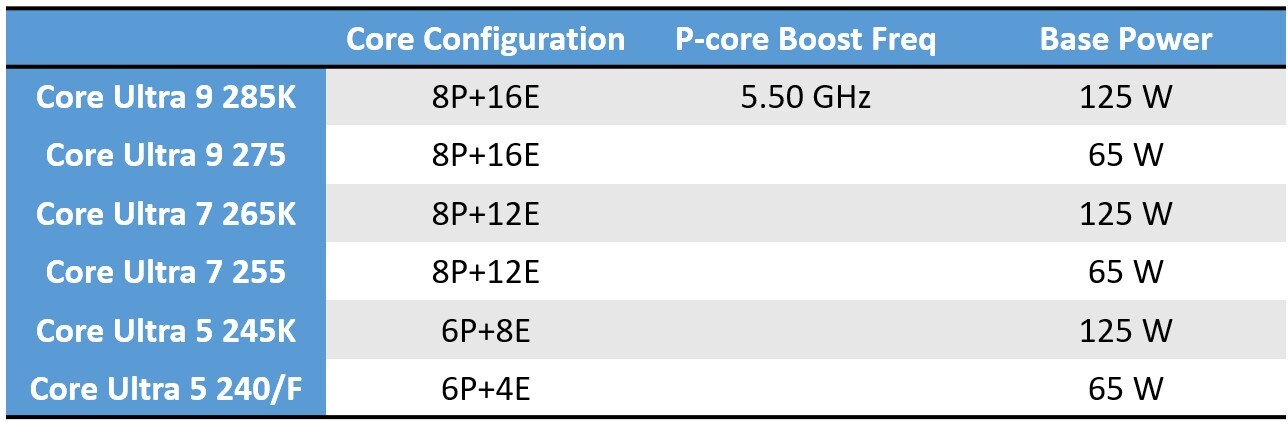
There are also some 65 W non-K models in the middle, although these don't have similar processor model numbers to the K/KF parts. There's the Core Ultra 9 275 (8P+16E, 65 W); the Core Ultra 7 255 (8P+12E, 65 W); and the Core Ultra 5 240 (6P+4E, 65 W).
"Arrow Lake" is a chiplet-based processor, just like "Meteor Lake." Its compute tile, the piece of silicon with the CPU cores, packs up to 8 "Lion Cove" performance cores (P-cores), and up to 16 "Skymont" efficiency cores (E-cores). The processor is also expected to feature a 50 TOPS-class NPU for on-device AI acceleration, and a truncated version of the Xe-LPG iGPU the company is using with "Meteor Lake," which could be branded differently from the Arc Graphics branding Intel is using on the Core Ultra 100 series mobile chips. "Arrow Lake" is also expected to debut a new CPU socket on the desktop platform, the LGA1851, with more I/O capabilities than the LGA1700 and "Raptor Lake."
101 Comments on Core Configurations of Intel Core Ultra 200 "Arrow Lake-S" Desktop Processors Surface
a) The CPUs are ready for "imminent" release (within the next couple of months)
or
b) This is yet another fake leak
Please keep this in mind.You are raising excellent questions, which no one can answer until we get a deep-dive into actual finalized products, but I can still point out a few important aspects most people miss;
Firstly, given Arrow Lake is presumably a very different microarchitecture, we don't know its performance characteristics at all, and even if we got confirmed IPC figures, base clocks and boost clocks, amount of cache etc., it only gives us an idea of the overall performance, but still very little whether this is an all-round excellent performer, or only excels in computationally heavy (but logically simple) SIMD, or very good at mixed loads but not at heavy SIMD. It may very well end up like a stellar performer in synthetic or very specific benchmarks, and just being a modest upgrade in real world tasks, only time will tell. When it comes to E-cores, those are already mostly a gimmick. They serve two purposes; make the specs look nice, like having >5 GHz 20 cores at 65W (the big PC vendors loves this), and to make certain benchmarks like Cinebench look good (which have little or no relevance for end-users).
We also need to keep in mind when they do (presumably) larger architectural overhauls there might actually be areas with significant downsides too, especially with the "first iteration", so be mentally prepared for that, and don't completely dismiss large advancements in some areas if there are some regressions too. Additionally, despite IPC and rated clock speeds, the microarchitecture and the node ultimately decides which performance will be achieved in specific workloads. Contrary to popular belief, IPC is actually an average amount of instructions, not performance at all. Plus, the node and the microarchitecture might allow the CPU to run a specific workload at a higher than expected sustained real clock speed than a competitor with similar or even higher "IPC". This was the case back with Zen 2 vs. Coffee Lake/Comet Lake, where in many multithreaded workloads Zen 2 achieved much higher actual clock speeds, while the Skylake-family throttled heavily despite higher IPC, resulting in lower performance for Intel. And IPC estimates based on rated clock speeds is useless, as rated clock speeds on current CPUs is mostly a gimmick anyways. This is why I always say; performance is what ultimately matters, how it's achieved is just details for those interested. ;)Lots of good info there. Just keep in mind that any graphics used in promotional material prior to release may very well be based on approximations, not the final design. ;)
The Lunarlake graphic represents LionCove's diagrams very accurately. Why do I think it's very accurate? Because the main LionCove project has been completed for some time and will also be implemented in ArrowLake.
I dare say that the same diagrams come from the preparation for the presentation of the LionCove microarchitecture.
Modern Zen cores(as well as Intel ones) have highly refined SMT implementations, with many resources as possible being competitively shared and etc. This is going to cost a lot of transistors, engineering hours, validation, heat and etc.
Intel might have run simulations and thought from the results that further SMT might just be take more than it adds.You are not guaranteed to lose performance, and can gain from it. It depends too much on workload, SMT would benefit the most when there are stalls in places like memory or you have threads that have very different resource utilization(say, one is purely integer and the other is majority float).
By disabling SMT, you are giving the entire core resources to a single thread, and that might have been the bottleneck for a lot of things, including some MT workloads.
Honestly, what really interests me is what AMD chooses to do in response: will they stick with HT and their lighter-weight Zen cores, will they try their own heterogenous approach, will they come up with something completely different, will they do all or none of the above?
At least Intel is trying something new, moving from monolithic, and no more HT. I think Arrow Lake will surprise us all.
There are a lot of ways to implement SMT/HT and they have different costs-performance considerations. The PS3 and Xbox360 had SMT too and they did that because the architecture would have been too prone to single core stalls otherwise..
It's not necessarily a lightweight thing to implement.
I think that honestly in terms of Architecture, Intel has never got behind really. Skylake was great for many years, they just really got behind in terms of lithography. So if they are deciding that HT isn't worth it anymore, I would really assume they have good reasons to believe so.
These guys look to be the first to bring backside power delivery/powerVIA and gate all around/ribbonFET transistors to mass market. This is not an insignificant achievement. Intel were also the first to bring hybrid architecture to consumer mainstream x86 PCs with the SoC lakefield, which incorporated foveros, two types of cores, IO and DRAM on a single chip in 2020 before M1.
No, they aren't choosing to end HT from a complete lack of understanding of how these things work. Please, get real.
A lot of details are hard and requires adjustements. I would suggest to take a look at the SMT section of this article:
Loongson 3A6000: A Star among Chinese CPUs – Chips and Cheese
It might not seem much, but it can affect the schedulers and everything which becomes significantly more complex as they now have to check and schedule from two separated threads.
Obviously, when you consider L2, that is going to be as big if not bigger than the core. But the impact might be similar or somewhat greater than the PS5 FPU nerf. If they can then use that transistor budget for other things, you could see some benefit.
The Nerfed FPU in PS5’s Zen 2 Cores – Chips and Cheese
Secondly is context, you're implying when tuning and turning off HT, voltage/frequency imrprovements are "not automatic", right, this does not make my original statement "factually incorrect".
This is a different situation to having out of the box HT disabled/not architecturally designed in, therefore voltage/frequency improvements would be "baked in" to the microcode.
Your statement "but you lose performance" is also, how do you put it "factually incorrect" in the same way my original statement was. It depends. In many processes and games, disabling HT even with no other changes/tunes made, will improve performance on something like a 13900K.
Finally, you are assuming it's you I'm referring to when I say "people/armchair critics seem to think they know better than Intel researchers and engineers", this is a projection on your part. I was not even thinking of you when I wrote this.
The bottom line is HT benefits software when additional MT performance is needed, but has drawbacks when that MT performance is not needed and there are enough cores/threads even without HT. How often do you think that is the case in a 24 core CPU?
If you want to test the "Without it you can clock higher, use less voltage" assertion.
Get a Raptor Lake CPU, set a static frequency. Now tune the voltage until you're unstable. Note that voltage.
Now turn off HT.
Tune the voltage again.
Note the voltage.
You can do the same thing for clocks etc.
If Intel delivers a CPU without HT that performs better in applications and games that the previous generation, and is more secure. It's a win.
Secondly, you said without SMT you can design CPU's that can clock higher, use less volts. That's not true as it again, depends on the arch.
When I said lose performance, that's incorrect and it's not what I was trying to say. If you read my post, I was trying to imply that maybe an architecture designed with SMT in mind might lose performance which in turn will allow those clocks. Or it might be the transistors that are idle now and depending on the grey silicon can help with thermals/hotspots. It might be reduced utilization, or CPU cores not fighting for cache. It can be a multitude of things. But it doesn't change the fact that you said having no SMT will lead to higher clocks/lower volts which is still incorrect because, again, it depends on how a CPU is designed and may or may not lead to higher clocks.
Regarding your last sentence alluding to HT only increasing multithreaded performance and when you already have 24 cores you don't need more of it, that's not really true is it? If the architecture is designed with SMT in mind, then regardless of the fact that consumers don't need more than 24 cores it will be on by default because it'll lead to better numbers per core because they need to extract TLP as the core can handle two concurrent instruction streams and still not be starved of resources (relatively). But maybe intel saw that they don't need SMT anymore because they can design an arch that will go around the reasons as to why SMT is needed in the first place and that's fine.
edit: I see that you're still trying to argue with the clock higher part in an edited post of yours. Let me try to make it easy for you - you said without SMT you can design a core that uses less volts and have higher clocks. I said that's not correct because it entirely depends on how the architecture is designed. Having an arch that is perfect and extracts the maximum from a thread will not require SMT, but it doesn't mean it'll also clock higher in the process. You're now trying to say disabling SMT leads to higher clocks, which is a different thing entirely and I said as much - there are a number of reasons why that might be the case
Have a nice day.
As to a "clean room" design, I doubt any of big CPU designers will start that much from scratch, but they do however have to make the big design decisions in the very beginning of the design process, like how threading will work, how cores are interacting etc., as all other design decisions are resulting from that, although they probably don't have the resources to redesign and finetune every tiny part of the CPU design in the first try. So deciding to ditch SMT certainly was done early on, but I would expect them to need a few "attempts" to fully break free from all the design constraints and unleash new levels of IPC. :)
Looking forward, there will be a lot of advancements in superscalar execution. I know Intel are looking into strategies to lessen the impact of branch mispredictions and avoid pipeline stalls and flushes. I believe some of this was supposed to show up in Meteor Lake, but I haven't studied whether it is and the success of it. But over the next generations, we should expect there to be significant gains.Just for the sake of being correct, Rocket Lake wasn't a regression in terms of overall performance, it offered ~19% IPC gains and similar clocks, but sacrificed 2 cores vs. Comet Lake, which leads to people thinking it was inferior. Rocket Lake which was a "backport" of Ice Lake to 14nm was greatly held back by this "inferior" node. The whole family is called "Sunny Cove", with Ice Lake being released in 2019 (server only, very limited availability), followed by Tiger Lake which was a small architectural improvement. Rocket Lake surprisingly seems to be a derivative of Ice Lake-S(never finalized) rather than Tiger Lake, I assume because Tiger Lake never was designed for this purpose and it was much quicker to backport Ice Lake-S instead.