Wednesday, August 24th 2022

Latency Increase from Larger L2 Cache on Intel "Raptor Cove" P-core Well Contained: Report
According to an investigative report by "Chips and Cheese," the larger L2 caches in Intel's 13th Gen Core "Raptor Lake-S" doesn't come with a proportionate increase in cache latency, and Intel seems to have contained the latency increase well. "Raptor Lake-S" significantly increases L2 cache sizes over the previous generation. Each of its 8 "Raptor Cove" P-cores has 2 MB of dedicated L2 cache, compared to the 1.25 MB with the "Golden Cove" P-cores powering the current-gen "Alder Lake-S," which amounts to a 60 percent increase in size. The "Gracemont" E-core clusters (group of four E-cores), sees a doubling in the size of the L2 cache that's shared among the four cores in the cluster, from 2 MB in "Alder Lake," to 4 MB. The last-level L3 cache shared among all P-cores and E-core clusters, sees a less remarkable increase in size, from 30 MB to 36 MB.
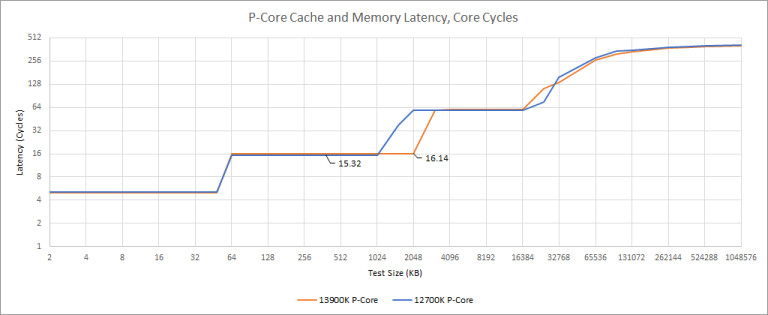
Larger caches have a direct impact on performance, as more data is available close to the CPU cores, sparing them a lengthy fetch/store operation to the main memory (RAM). However, making caches larger doesn't just cost die-area, transistor-count, and power/heat, but also latency, even though L2 cache is an order of magnitude faster than the L3 cache, which in turn is significantly faster than DRAM. Chips and Cheese tracked and tabulated the L2 cache latencies of past Intel client microarchitectures, and found a generational increase in latencies with increasing L2 cache sizes, leading up to "Alder Lake." This increase has somehow tapered with "Raptor Lake."
 The report says that the 4-way associative 256 KB dedicated L2 cache with "Skylake" (thru "Comet Lake") CPU cores has an L2 cache latency of 12 cycles. "Sunny Cove" and "Cypress Cove" cores see this increase to 512 KB in size, as the latency is increased to 13 cycles. "Willow Cove" and "Golden Cove" (powering "Tiger Lake" and "Alder Lake," respectively), see a further increase. While "Willow Cove" uses a 20-way associative cache, "Golden Cove" uses 10-way. The latency goes up from 13 cycles to 14 cycles. The upcoming "Raptor Cove" P-core comes with 2 MB of 16-way L2 cache, but here, the latency is contained to 15 cycles. It indicates that "Raptor Lake" has undergone some serious rework with its power-management as well as cache design to reach its cache latency target. Bear in mind, that this chip is built on the same 10 nm Enhanced SuperFin (Intel 7) node as "Alder Lake."
The report says that the 4-way associative 256 KB dedicated L2 cache with "Skylake" (thru "Comet Lake") CPU cores has an L2 cache latency of 12 cycles. "Sunny Cove" and "Cypress Cove" cores see this increase to 512 KB in size, as the latency is increased to 13 cycles. "Willow Cove" and "Golden Cove" (powering "Tiger Lake" and "Alder Lake," respectively), see a further increase. While "Willow Cove" uses a 20-way associative cache, "Golden Cove" uses 10-way. The latency goes up from 13 cycles to 14 cycles. The upcoming "Raptor Cove" P-core comes with 2 MB of 16-way L2 cache, but here, the latency is contained to 15 cycles. It indicates that "Raptor Lake" has undergone some serious rework with its power-management as well as cache design to reach its cache latency target. Bear in mind, that this chip is built on the same 10 nm Enhanced SuperFin (Intel 7) node as "Alder Lake."
Source:
Chips and Cheese
Larger caches have a direct impact on performance, as more data is available close to the CPU cores, sparing them a lengthy fetch/store operation to the main memory (RAM). However, making caches larger doesn't just cost die-area, transistor-count, and power/heat, but also latency, even though L2 cache is an order of magnitude faster than the L3 cache, which in turn is significantly faster than DRAM. Chips and Cheese tracked and tabulated the L2 cache latencies of past Intel client microarchitectures, and found a generational increase in latencies with increasing L2 cache sizes, leading up to "Alder Lake." This increase has somehow tapered with "Raptor Lake."

13 Comments on Latency Increase from Larger L2 Cache on Intel "Raptor Cove" P-core Well Contained: Report
That's all.
As tCWL is good for one thing on AM4; causing instability - "nooo i don't wanna do tCL 13 with tCWL 12 that's too fast" meanwhile tCWL > tCL is hella unstable (e.g. tCL 13 + tCWL 14 POSTs, unlike tCWL 12) - and generally being a waste of time to mess with.
Conspicuously then tCWL can be run above tCL on Alder Lake, up to around +3.. Hmm......
oh right, and I should leave my obligatory "these processors run Cool & Quiet just fine if you dial in the RAM settings real hard" comment too, i guess
bah
The current chip I have can hit 5.4 with no issues and it was a first batch 12600k bin. I think they sacrificed clocks for volumes in the initial process, and if you think about the top 12900k bins, the jump from 5.4/5.5 ghz to 5.6 ghz is much less impressive.
Rather, Zen4 is clocking up enough to offset the power efficiency improvements due to node advancements, and the power efficiency of RPL and Zen4 will be similar.
It will be interesting to see if future microarchitectures tries to add even more banks, as the efficiency will be dropping off at some point. Future nodes may make it feasible though to increase the bank size instead.Which modifications are you thinking of?
At least the design process of Golden Cove (the big cores) were very long, >5 years.
- Data transfer, such as
- cache (written in the spec sheet)
- the ringbus (@OneRaichu already showed difference in core-to-core latency matrix between ADL and RPL)
- Optimization on clock-speed bottleneck
- e.g. logically same and electrically different things, such as adjusting the distance between components
For example, ADL had significantly slower decompress than compress with 7zip (compared to other CPU trends), but that problem has been eliminated with RPL. There are not a few reports of algorithm-dependent performance improvement differences between ADL and RPL, but I suspect that this is probably the effect of the elimination of the data transfer bottleneck.
It's not unusual to see improvements to a second iteration of a microarchitecture, and it's not uncommon for a design to have unforeseen bottlenecks, imbalances and even the odd regression. All the major design decisions are made long before they get to run the real hardware, and by then they can only do minor tweaks without causing years of delays.
It was pointed out that Alder lake had data transfer problems right after its launch. I first saw the article in my native language, but the following articles in English, for example, might be typical evaluation.
"Alder Lake – E-Cores, Ring Clock, and Hybrid Teething Troubles" by Chip and Cheese, December 16, 2021
Latency, in clock cycles -- is only directly comparable with equal frequencies.
Cache speeds have increased significantly.
For example, looking at Rocket Lake running a ring bus speed (cache frequency) of 5Ghz, we have:
16 clocks @5Ghz= (1/5,000,000,000)x16 =3.2 ns
There is more to the story than simply the frequency and that one timing, when it comes to real world latency, however.
Regardless, if you look at the measured L2 cache latency in aida 64 memory bench, for example -- you'll see that it hasn't changed much at all since skylake.